SpinKube documentation
Everything you need to know about SpinKube.
First steps
To get started with SpinKube, follow our Quickstart guide.
How the documentation is organized
SpinKube has a lot of documentation. A high-level overview of how it’s organized will help you know
where to look for certain things.
- Installation guides cover how to install SpinKube on various
platforms.
- Topic guides discuss key topics and concepts at a fairly high level and
provide useful background information and explanation.
- Reference guides contain technical reference for APIs and other
aspects of SpinKube’s machinery. They describe how it works and how to use it but assume that you
have a basic understanding of key concepts.
- Contributing guides show how to contribute to the SpinKube project.
- Miscellaneous guides cover topics that don’t fit neatly into either of
the above categories.
1 - Overview
A high level overview of the SpinKube sub-projects.
Project Overview
SpinKube is an open source project that streamlines the
experience of deploying and operating Wasm workloads on Kubernetes, using Spin
Operator in tandem with
runwasi and runtime class
manager.
With SpinKube, you can leverage the advantages of using WebAssembly (Wasm) for your workloads:
- Artifacts are significantly smaller in size compared to container images.
- Artifacts can be quickly fetched over the network and started much faster (*Note: We are aware of
several optimizations that still need to be implemented to enhance the startup time for
workloads).
- Substantially fewer resources are required during idle times.
Thanks to SpinKube, we can do all of this while integrating with Kubernetes primitives including
DNS, probes, autoscaling, metrics, and many more cloud native and CNCF projects.
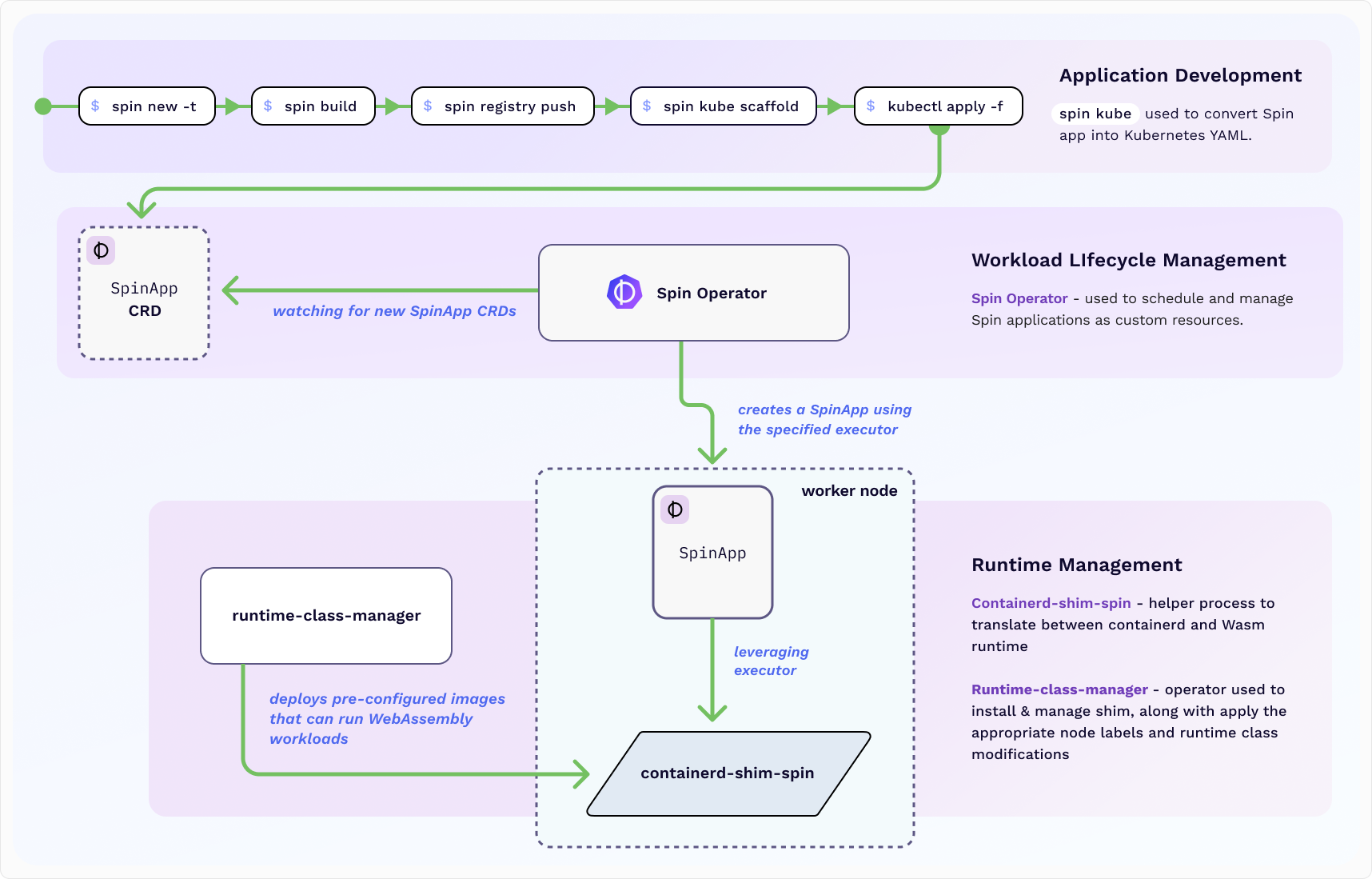
SpinKube watches Spin App Custom Resources and realizes
the desired state in the Kubernetes cluster. The foundation of this project was built using the
kubebuilder framework and contains a Spin App
Custom Resource Definition (CRD) and controller.
SpinKube is a Cloud Native Computing Foundation sandbox project.
To get started, check out our Quickstart guide.
2 - Installation
Before you can use SpinKube, you’ll need to get it installed. We have several complete installation guides that covers all the possibilities; these guides will guide you through the process of installing SpinKube on your Kubernetes cluster.
2.1 - Quickstart
Learn how to setup a Kubernetes cluster, install SpinKube and run your first Spin App.
This Quickstart guide demonstrates how to set up a development Kubernetes cluster, install SpinKube and
deploy your first Spin application. This example creates a kind cluster with the Spin containerd shim pre-installed on all nodes. In production, you should use the runtime class manager to install and manage the lifecycle of the containerd shim. Jump to the Helm installation for more production cluster installation instructions.
Prerequisites
For this Quickstart guide, you will need:
Set up Your Kubernetes Cluster
- Create a Kubernetes cluster with a kind image that includes the
containerd-shim-spin prerequisite already
installed. During creation of the kind cluster, we add containerd configuration to instruct containerd to use the Spin containerd shim for workloads scheduled with the
spin runtime class.:
cat <<EOF | kind create cluster --name wasm-cluster --image ghcr.io/spinframework/containerd-shim-spin/kind:v0.25.0 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
containerdConfigPatches:
- |-
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin]
runtime_type = "io.containerd.spin.v2"
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin.options]
SystemdCgroup = true
EOF
- Install cert-manager
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.yaml
kubectl wait --for=condition=available --timeout=300s deployment/cert-manager-webhook -n cert-manager
- Apply the Runtime
Class
used for scheduling Spin apps onto nodes running the shim:
Note: In a production cluster you likely want to customize the Runtime Class with a nodeSelector
that matches nodes that have the shim installed. However, in the kind example, the shim is pre-configured on
every node.
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.runtime-class.yaml
- Apply the Custom Resource Definitions
used by the Spin Operator:
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
Deploy the Spin Operator
Execute the following command to install the Spin Operator on the cluster using Helm. This will
create all of the Kubernetes resources required by Spin Operator under the Kubernetes namespace
spin-operator. It may take a moment for the installation to complete as dependencies are installed
and pods are spinning up.
# Install Spin Operator with Helm
helm upgrade --install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
Lastly, create the shim executor:
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Run the Sample Application
You are now ready to deploy Spin applications onto the cluster!
- Create your first application in the same
spin-operator namespace that the operator is running:
kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/simple.yaml
- Forward a local port to the application pod so that it can be reached:
kubectl port-forward svc/simple-spinapp 8083:80
- In a different terminal window, make a request to the application:
curl localhost:8083/hello
You should see:
Next Steps
Congrats on deploying your first SpinApp! Recommended next steps:
2.2 - Installing the `spin kube` plugin
Learn how to install the kube plugin.
The kube plugin for spin (The Spin CLI) provides first class experience for working with Spin
apps in the context of Kubernetes.
Prerequisites
Ensure you have the Spin CLI (version 2.3.1 or
newer) installed on your machine.
Install the plugin
Before you install the plugin, you should fetch the list of latest Spin plugins from the
spin-plugins repository:
# Update the list of latest Spin plugins
spin plugins update
Plugin information updated successfully
Go ahead and install the kube using spin plugin install:
# Install the latest kube plugin
spin plugins install kube
At this point you should see the kube plugin when querying the list of installed Spin plugins:
# List all installed Spin plugins
spin plugins list --installed
cloud 0.7.0 [installed]
cloud-gpu 0.1.0 [installed]
kube 0.1.1 [installed]
pluginify 0.6.1 [installed]
Compiling from source
As an alternative to the plugin manager, you can download and manually install the plugin. Manual
installation is commonly used to test in-flight changes. For a user, installing the plugin using
Spin’s plugin manager is better.
Please refer to the spin-plugin-kube GitHub
repository for instructions on how to compile the
plugin from source.
2.3 - Installing with Helm
This guide walks you through the process of installing SpinKube using
Helm.
Prerequisites
For this guide in particular, you will need:
- kubectl - the Kubernetes CLI
- Helm - the package manager for Kubernetes
Install Spin Operator With Helm
The following instructions are for installing Spin Operator using a Helm chart (using helm install).
Prepare the Cluster
Before installing the chart, you’ll need to ensure the following are installed:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.yaml
- Runtime Class Manager is required to install WebAssembly shims on Kubernetes nodes that don’t already include them. See more details at the project’s README.md.
# Install Runtime Class Manager
helm upgrade --install runtime-class-manager \
--namespace runtime-class-manager \
--create-namespace \
--version 0.2.0 \
oci://ghcr.io/spinframework/charts/runtime-class-manager
# Create Shim resource for installing the containerd-shim-spin binary
kubectl apply -f https://github.com/spinframework/containerd-shim-spin/releases/download/v0.25.1/runtime-class-manager-shim-v1alpha1-v0.25.1.yaml
# Label all Nodes where the shim should be installed (and thus where Spin Apps may run)
# Note: this specific key and value matches the nodeSelector configuration used in the Shim resource above
kubectl label node --all spin=true
You should now see a wasmtime-spin-v2 RuntimeClass and all labeled Nodes should be ready to run Spin Apps.
Chart prerequisites
Now we have our dependencies installed, we can start installing the operator. This involves a couple
of steps that allow for further customization of Spin Applications in the cluster over time, but
here we install the defaults.
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
- Finally, we create a
containerd-spin-shim SpinAppExecutor. This tells the Spin Operator to use the RuntimeClass we
just created to run Spin Apps:
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Installing the Spin Operator Chart
The following installs the chart with the release name spin-operator:
# Install Spin Operator with Helm
helm upgrade --install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
Head over to the Quickstart to deploy your first Spin App. Or, read on for how to upgrade or uninstall Spin Operator.
Upgrading the Chart
Note that you may also need to upgrade the spin-operator CRDs in tandem with upgrading the Helm
release:
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
To upgrade the spin-operator release, run the following:
# Upgrade Spin Operator using Helm
helm upgrade spin-operator \
--namespace spin-operator \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
Uninstalling the Chart
To delete the spin-operator release, run:
# Uninstall Spin Operator using Helm
helm delete spin-operator --namespace spin-operator
This will remove all Kubernetes resources associated with the chart and deletes the Helm release.
To completely uninstall all resources related to spin-operator, you may want to delete the
corresponding CRD resources:
kubectl delete -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
kubectl delete -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
2.4 - Installing on Azure Kubernetes Service
In this tutorial you’ll learn how to deploy SpinKube on Azure Kubernetes Service (AKS).
In this tutorial, you install Spin Operator on an Azure Kubernetes Service (AKS) cluster and deploy
a simple Spin application. You will learn how to:
- Deploy an AKS cluster
- Install Spin Operator Custom Resource Definitions
- Install and verify containerd shim via Runtime Class Manager
- Deploy a simple Spin App custom resource on your cluster
Prerequisites
Please ensure you have the following tools installed before continuing:
- kubectl - the Kubernetes CLI
- Helm - the package manager for Kubernetes
- Azure CLI - cross-platform CLI
for managing Azure resources
Provisioning the necessary Azure Infrastructure
Before you dive into deploying Spin Operator on Azure Kubernetes Service (AKS), the underlying cloud
infrastructure must be provisioned. For the sake of this article, you will provision a simple AKS
cluster. (Alternatively, you can setup the AKS cluster following this guide from
Microsoft.)
# Login with Azure CLI
az login
# Select the desired Azure Subscription
az account set --subscription <YOUR_SUBSCRIPTION>
# Create an Azure Resource Group
az group create --name rg-spin-operator \
--location germanywestcentral
# Create an AKS cluster
az aks create --name aks-spin-operator \
--resource-group rg-spin-operator \
--location germanywestcentral \
--node-count 1 \
--tier free \
--generate-ssh-keys
Once the AKS cluster has been provisioned, use the aks get-credentials command to download
credentials for kubectl:
# Download credentials for kubectl
az aks get-credentials --name aks-spin-operator \
--resource-group rg-spin-operator
For verification, you can use kubectl to browse common resources inside of the AKS cluster:
# Browse namespaces in the AKS cluster
kubectl get namespaces
NAME STATUS AGE
default Active 3m
kube-node-lease Active 3m
kube-public Active 3m
kube-system Active 3m
Deploying the Spin Operator
First, the Custom Resource Definition (CRD)
and the Runtime Class for wasmtime-spin-v2 must be
installed.
# Install the CRDs
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
The following installs cert-manager which is
required to automatically provision and manage TLS certificates (used by the admission webhook
system of Spin Operator)
# Install cert-manager CRDs
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.crds.yaml
# Add and update Jetstack repository
helm repo add jetstack https://charts.jetstack.io
helm repo update
# Install the cert-manager Helm chart
helm upgrade --install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.20.0
The Spin Operator chart also has a dependency on Runtime Class Manager, which is used to install the containerd Spin shim on the Kubernetes node(s):
# Install Runtime Class Manager
helm upgrade --install runtime-class-manager \
--namespace runtime-class-manager \
--create-namespace \
--version 0.2.0 \
oci://ghcr.io/spinframework/charts/runtime-class-manager
# Create Shim resource for installing the containerd-shim-spin binary
kubectl apply -f https://github.com/spinframework/containerd-shim-spin/releases/download/v0.25.1/runtime-class-manager-shim-v1alpha1-v0.25.1.yaml
# Label all Nodes where the shim should be installed (and thus where Spin Apps may run)
# Note: this specific key and value matches the nodeSelector configuration used in the Shim resource above
kubectl label node --all spin=true
To verify containerd-shim-spin installation, you can inspect the status of the Shim resource as updated by Runtime Class Manager:
# Inspect the Shim resource
kubectl get shim spin-v2 --no-headers -o custom-columns=":status.nodesReady"
The command above should return the same number of Nodes in your cluster (i.e. as labeled in the step above).
The following installs the chart with the release name spin-operator in the spin-operator
namespace:
helm upgrade --install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
Lastly, create the shim executor::
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Deploying a Spin App to AKS
To validate the Spin Operator deployment, you will deploy a simple Spin App to the AKS cluster. The
following command will install a simple Spin App using the SpinApp CRD you provisioned in the
previous section:
# Deploy a sample Spin app
kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/simple.yaml
Verifying the Spin App
Configure port forwarding from port 8080 of your local machine to port 80 of the Kubernetes
service which points to the Spin App you installed in the previous section:
kubectl port-forward services/simple-spinapp 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
Send a HTTP request to http://127.0.0.1:8080/hello using
curl:
# Send an HTTP GET request to the Spin App
curl -iX GET http://localhost:8080/hello
HTTP/1.1 200 OK
transfer-encoding: chunked
date: Mon, 12 Feb 2024 12:23:52 GMT
Hello world from Spin!%
Removing the Azure infrastructure
To delete the Azure infrastructure created as part of this article, use the following command:
# Remove all Azure resources
az group delete --name rg-spin-operator \
--no-wait \
--yes
2.5 - Installing on Linode Kubernetes Engine (LKE)
This guide walks you through the process of installing SpinKube on
LKE.
This guide walks through the process of installing and configuring SpinKube on Linode Kubernetes
Engine (LKE).
Prerequisites
This guide assumes that you have an Akamai Linode account that is
configured and has sufficient permissions for creating a new LKE cluster.
You will also need recent versions of kubectl and helm installed on your system.
Creating an LKE Cluster
LKE has a managed control plane, so you only need to create the pool of worker nodes. In this
tutorial, we will create a 2-node LKE cluster using the smallest available worker nodes. This should
be fine for installing SpinKube and running up to around 100 Spin apps.
You may prefer to run a larger cluster if you plan on mixing containers and Spin apps, because
containers consume substantially more resources than Spin apps do.
In the Linode web console, click on Kubernetes in the right-hand navigation, and then click
Create Cluster.

You will only need to make a few choices on this screen. Here’s what we have done:
- Cluster name: We named the cluster
spinkube-lke-1. You should name it according to whatever
convention you prefer. - Region: We chose the
Chicago, IL (us-ord) region, but you can choose any region you prefer. - Kubernetes Version: The latest supported Kubernetes version is
1.30, so we chose that. - High Availability Control Plane: For this testing cluster, we chose
No on HA Control Plane
because we do not need high availability. - Node Pool configuration: In
Add Node Pools, we added two Dedicated 4 GB simply to show a
cluster running more than one node. Two nodes is sufficient for Spin apps, though you may prefer
the more traditional 3 node cluster. Click Add to add these, and ignore the warning about
minimum sizes.
Once you have set things to your liking, click Create Cluster.
This will take you to a screen that shows the status of the cluster. Initially, you will want to
wait for all of your Node Pool to start up. Once all of the nodes are online, download the
kubeconfig file, which will be named something like spinkube-lke-1-kubeconfig.yaml.
The kubeconfig file will have the credentials for connecting to your new LKE cluster. Do not
share that file or put it in a public place.
For all of the subsequent operations, you will want to use the spinkube-lke-1-kubeconfig.yaml as
your main Kubernetes configuration file. The best way to do that is to set the environment variable
KUBECONFIG to point to that file:
$ export KUBECONFIG=/path/to/spinkube-lke-1-kubeconfig.yaml
You can test this using the command kubectl config view:
$ kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://REDACTED.us-ord-1.linodelke.net:443
name: lke203785
contexts:
- context:
cluster: lke203785
namespace: default
user: lke203785-admin
name: lke203785-ctx
current-context: lke203785-ctx
kind: Config
preferences: {}
users:
- name: lke203785-admin
user:
token: REDACTED
This shows us our cluster config. You should be able to cross-reference the lkeNNNNNN version with
what you see on your Akamai Linode dashboard.
Install SpinKube Using Helm
At this point, install SpinKube with Helm. As long as your KUBECONFIG
environment variable is pointed at the correct cluster, the installation method documented there
will work.
Once you are done following the installation steps, return here to install a first app.
Creating a First App
We will use the spin kube plugin to scaffold out a new app. If you run the following command and
the kube plugin is not installed, you will first be prompted to install the plugin. Choose yes
to install.
We’ll point to an existing Spin app, a Hello World program written in
Rust, compiled to Wasm, and stored in
GitHub Container Registry (GHCR):
$ spin kube scaffold --from ghcr.io/spinkube/containerd-shim-spin/examples/spin-rust-hello:v0.13.0 > hello-world.yaml
Note that Spin apps, which are WebAssembly, can be stored in most container
registries even though they are not
Docker containers.
This will write the following to hello-world.yaml:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: spin-rust-hello
spec:
image: "ghcr.io/spinkube/containerd-shim-spin/examples/spin-rust-hello:v0.13.0"
executor: containerd-shim-spin
replicas: 2
Using kubectl apply, we can deploy that app:
$ kubectl apply -f hello-world.yaml
spinapp.core.spinkube.dev/spin-rust-hello created
With SpinKube, SpinApps will be deployed as Pod resources, so we can see the app using kubectl get pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spin-rust-hello-f6d8fc894-7pq7k 1/1 Running 0 54s
spin-rust-hello-f6d8fc894-vmsgh 1/1 Running 0 54s
Status is listed as Running, which means our app is ready.
Making An App Public with a NodeBalancer
By default, Spin apps will be deployed with an internal service. But with Linode, you can provision
a NodeBalancer using a Service
object. Here is a hello-world-service.yaml that provisions a nodebalancer for us:
apiVersion: v1
kind: Service
metadata:
name: spin-rust-hello-nodebalancer
annotations:
service.beta.kubernetes.io/linode-loadbalancer-throttle: "4"
labels:
core.spinkube.dev/app-name: spin-rust-hello
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
core.spinkube.dev/app.spin-rust-hello.status: ready
sessionAffinity: None
When LKE receives a Service whose type is LoadBalancer, it will provision a NodeBalancer for
you.
You can customize this for your app simply by replacing all instances of spin-rust-hello with
the name of your app.
We can create the NodeBalancer by running kubectl apply on the above file:
$ kubectl apply -f hello-world-nodebalancer.yaml
service/spin-rust-hello-nodebalancer created
Provisioning the new NodeBalancer may take a few moments, but we can get the IP address using
kubectl get service spin-rust-hello-nodebalancer:
$ get service spin-rust-hello-nodebalancer
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
spin-rust-hello-nodebalancer LoadBalancer 10.128.235.253 172.234.210.123 80:31083/TCP 40s
The EXTERNAL-IP field tells us what the NodeBalancer is using as a public IP. We can now test this
out over the Internet using curl or by entering the URL http://172.234.210.123/hello into your
browser.
$ curl 172.234.210.123/hello
Hello world from Spin!
Deleting Our App
To delete this sample app, we will first delete the NodeBalancer, and then delete the app:
$ kubectl delete service spin-rust-hello-nodebalancer
service "spin-rust-hello-nodebalancer" deleted
$ kubectl delete spinapp spin-rust-hello
spinapp.core.spinkube.dev "spin-rust-hello" deleted
If you delete the NodeBalancer out of the Linode console, it will not automatically delete the
Service record in Kubernetes, which will cause inconsistencies. So it is best to use kubectl delete service to delete your NodeBalancer.
If you are also done with your LKE cluster, the easiest way to delete it is to log into the Akamai
Linode dashboard, navigate to Kubernetes, and press the Delete button. This will destroy all of
your worker nodes and deprovision the control plane.
2.6 - Installing on Rancher Desktop
This tutorial shows how to integrate SpinKube and Rancher Desktop.
Rancher Desktop is an open-source application that provides all the
essentials to work with containers and Kubernetes on your desktop.
Prerequisites
- An operating system compatible with Rancher Desktop (Windows, macOS, or Linux).
- Administrative or superuser access on your computer.
Step 1: Installing Rancher Desktop
- Download Rancher Desktop:
- Navigate to the Rancher Desktop releases
page. We tested this documentation with Rancher Desktop
1.19.1 with Spin v3.2.0, but it should work with more recent versions. - Select the appropriate installer for your operating system.
- Install Rancher Desktop:
- Run the downloaded installer and follow the on-screen instructions to complete the
installation.
- Open Rancher Desktop
- Configure
containerd as your container runtime engine (under Preferences -> Container Engine). - Make sure that the Enable Wasm option is checked in the Preferences → Container Engine
section. Remember to always apply your changes.

- Navigate to the Preferences -> Kubernetes menu.
- Enable Kubernetes, Traefik and Spin Operator (under Preferences -> Kubernetes ensure that the Enable Kubernetes, Enable Traefik and Install Spin Operator options are checked.)

Make sure to select rancher-desktop from your Kubernetes contexts: kubectl config use-context rancher-desktop
Once your changes have been applied, go to the Cluster Dashboard -> Workloads. You should see the spin-operator-controller-manager deployed to the spin-operator namespace.
Step 3: Creating a Spin Application
- Open a terminal (Command Prompt, Terminal, or equivalent based on your OS).
- Create a new Spin application: This command creates a new Spin application using the
http-js template, named hello-k3s.
$ spin new -t http-js hello-k3s --accept-defaults
$ cd hello-k3s
- We can edit the
/src/index.js file and make the workload return a string “Hello from Rancher Desktop”:
import { AutoRouter } from 'itty-router';
let router = AutoRouter();
router
.get("/", () => new Response("Hello from Rancher Desktop")) // <-- this changed
.get('/hello/:name', ({ name }) => `Hello, ${name}!`)
addEventListener('fetch', (event) => {
event.respondWith(router.fetch(event.request));
});
Step 4: Deploying Your Application
- Push the application to a registry:
$ npm install
$ spin build
$ spin registry push ttl.sh/hello-k3s:0.1.0
Replace ttl.sh/hello-k3s:0.1.0 with your registry URL and tag.
- Deploy your Spin application to the cluster:
Use the spin-kube plugin to deploy your application to the cluster
spin kube scaffold --from ttl.sh/hello-k3s:0.1.0 | kubectl apply -f -
If we click on the Rancher Desktop’s “Cluster Dashboard”, we can see hello-k3s is running inside
the “Workloads” dropdown section:

To access our app outside of the cluster, we can forward the port so that we access the application
from our host machine:
$ kubectl port-forward svc/hello-k3s 8083:80
To test locally, we can make a request as follows:
$ curl localhost:8083
Hello from Rancher Desktop
The above curl command or a quick visit to your browser at localhost:8083 will return the “Hello
from Rancher Desktop” message:

2.7 - Installing on Microk8s
This guide walks you through the process of installing SpinKube using
Microk8s.
This guide walks through the process of installing and configuring Microk8s and SpinKube.
Prerequisites
This guide assumes you are running Ubuntu 24.04, and that you have Snap enabled (which is the
default).
The testing platform for this installation was an Akamai Edge Linode running 4G of memory and 2
cores.
Installing Spin
You will need to install Spin. The easiest way is
to just use the following one-liner to get the latest version of Spin:
$ curl -fsSL https://developer.fermyon.com/downloads/install.sh | bash
Typically you will then want to move spin to /usr/local/bin or somewhere else on your $PATH:
$ sudo mv spin /usr/local/bin/spin
You can test that it’s on your $PATH with which spin. If this returns blank, you will need to
adjust your $PATH variable or put Spin somewhere that is already on $PATH.
A Script To Do This
If you would rather work with a shell script, you may find this
Gist
a great place to start. It installs Microk8s and SpinKube, and configures both.
Installing Microk8s on Ubuntu
Use snap to install microk8s:
$ sudo snap install microk8s --classic
This will install Microk8s and start it. You may want to read the official installation
instructions before proceeding. Wait for a moment or two,
and then ensure Microk8s is running with the microk8s status command.
Next, enable the TLS certificate manager:
$ microk8s enable cert-manager
Now we’re ready to install the SpinKube environment for running Spin applications.
Installing SpinKube
SpinKube provides the entire toolkit for running Spin serverless apps. You may want to familiarize
yourself with the SpinKube quickstart guide
before proceeding.
First, we need to apply the CRDs for SpinKube:
$ microk8s kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
These should apply immediately.
We then need to install Runtime Class Manager because it is not yet included with Microk8s. It handles installing WebAssembly shims on Kubernetes nodes that don’t already include them. See more details at the project’s README.md.
microk8s helm upgrade --install runtime-class-manager \
--namespace runtime-class-manager \
--create-namespace \
--version 0.2.0 \
oci://ghcr.io/spinframework/charts/runtime-class-manager
# Create Shim resource for installing the containerd-shim-spin binary
kubectl apply -f https://github.com/spinframework/containerd-shim-spin/releases/download/v0.25.1/runtime-class-manager-shim-v1alpha1-v0.25.1.yaml
# Label all Nodes where the shim should be installed (and thus where Spin Apps may run)
# Note: this specific key and value matches the nodeSelector configuration used in the Shim resource above
microk8s kubectl label node --all spin=true
The last line above tells Microk8s that all nodes on the cluster (which is just one node in this
case) can run Spin applications.
Next, we need to install SpinKube’s operator using Helm (which is included with Microk8s).
$ microk8s helm upgrade --install spin-operator --namespace spin-operator --create-namespace --version 0.6.1 --wait oci://ghcr.io/spinframework/charts/spin-operator
Now we have the main operator installed. There is just one more step. We need to install the shim
executor, which is a special CRD that allows us to use multiple executors for WebAssembly.
$ microk8s kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Now SpinKube is installed!
Running an App in SpinKube
Next, we can run a simple Spin application inside of Microk8s.
While we could write regular deployments or pod specifications, the easiest way to deploy a Spin app
is by creating a simple SpinApp resource. Let’s use the simple example from SpinKube:
$ microk8s kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/simple.yaml
The above installs a simple SpinApp YAML that looks like this:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: simple-spinapp
spec:
image: "ghcr.io/spinkube/containerd-shim-spin/examples/spin-rust-hello:v0.13.0"
replicas: 1
executor: containerd-shim-spin
You can read up on the definition in the
documentation.
It may take a moment or two to get started, but you should be able to see the app with microk8s kubectl get pods.
$ microk8s kubectl get po
NAME READY STATUS RESTARTS AGE
simple-spinapp-5c7b66f576-9v9fd 1/1 Running 0 45m
Troubleshooting
If STATUS gets stuck in ContainerCreating, it is possible that Runtime Class Manager did not install
the containerd-shim-spin binary correctly. To see the logs, try:
$ microk8s kubectl logs -n runtime-class-manager -l app.kubernetes.io/name=runtime-class-manager
Testing the Spin App
The easiest way to test our Spin app is to port forward from the Spin app to the outside host:
$ microk8s kubectl port-forward services/simple-spinapp 8080:80
You can then run curl localhost:8080/hello
$ curl localhost:8080/hello
Hello world from Spin!
Where to go from here
So far, we installed Microk8s, SpinKube, and a single Spin app. To have a more production-ready
version, you might want to:
Bonus: Configuring Microk8s ingress
Microk8s includes an NGINX-based ingress controller that works great with Spin applications.
Enable the ingress controller: microk8s enable ingress
Now we can create an ingress that routes our traffic to the simple-spinapp app. Create the file
ingress.yaml with the following content. Note that the service.name is
the name of our Spin app.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: http-ingress
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: simple-spinapp
port:
number: 80
Install the above with microk8s kubectl -f ingress.yaml. After a moment or two, you should be able
to run curl [localhost](http://localhost) and see Hello World!.
Conclusion
In this guide we’ve installed Spin, Microk8s, and SpinKube and then run a Spin application.
To learn more about the many things you can do with Spin apps, go to the Spin developer
docs. You can also look at a variety of examples at Spin Up
Hub.
Or to try out different Kubernetes configurations, check out other installation
guides.
2.8 - Executor Compatibility Matrices
A set of compatibility matrices for each SpinKube executor
containerd-shim-spin Executor
The Spin containerd shim project is a containerd shim implementation for Spin.
Spin Operator and Shim Feature Map
If a feature is configured in a SpinApp that is not supported in the version of the shim being
used, the application may not execute as expected. The following maps out the versions of the Spin
containerd shim, Spin Operator, and spin kube
plugin that have support for specific features.
| Feature | SpinApp Field | Shim Version | Spin Operator Version | spin kube Plugin Version |
|---|
| OTEL Traces | otel | v0.15.0 | v0.3.0 | NA |
| Selective Deployment | components | v0.17.0 | v0.4.0 | v0.3.0 |
| Invocation Limits | invocationLimits | v0.20.0 | v0.6.0 | NA |
NA indicates that the feature in not available yet in that project
Spin and Spin Containerd Shim Version Map
For tracking the availability of Spin features and compatibility of Spin SDKs, the following
indicates which versions of the Spin runtime the Spin containerd
shim uses.
3 - Using SpinKube
Introductions to all the key parts of SpinKube you’ll need to know.
3.1 - Selective Deployments in Spin
Learn how to deploy a subset of components from your SpinApp using Selective Deployments.
This article explains how to selectively deploy a subset of components from your Spin App using Selective Deployments. You will learn how to:
- Scaffold a Specific Component from a Spin Application into a Custom Resource
- Run a Selective Deployment
Selective Deployments allow you to control which components within a Spin app are active for a specific instance of the app. With Component Selectors, Spin and SpinKube can declare at runtime which components should be activated, letting you deploy a single, versioned artifact while choosing which parts to enable at startup. This approach separates developer goals (building a well-architected app) from operational needs (optimizing for specific infrastructure).
Prerequisites
For this tutorial, you’ll need:
Scaffold a Specific Component from a Spin Application into a Custom Resource
We’ll use a sample application called “Salutations”, which demonstrates greetings via two components, each responding to a unique HTTP route. If we take a look at the application manifest, we’ll see that this Spin application is comprised of two components:
Hello component triggered by the /hi routeGoodbye component triggered by the /bye route
spin_manifest_version = 2
[application]
name = "salutations"
version = "0.1.0"
authors = ["Kate Goldenring <kate.goldenring@fermyon.com>"]
description = "An app that gives salutations"
[[trigger.http]]
route = "/hi"
component = "hello"
[component.hello]
source = "../hello-world/main.wasm"
allowed_outbound_hosts = []
[component.hello.build]
command = "cd ../hello-world && tinygo build -target=wasi -gc=leaking -no-debug -o main.wasm main.go"
watch = ["**/*.go", "go.mod"]
[[trigger.http]]
route = "/bye"
component = "goodbye"
[component.goodbye]
source = "main.wasm"
allowed_outbound_hosts = []
[component.goodbye.build]
command = "tinygo build -target=wasi -gc=leaking -no-debug -o main.wasm main.go"
watch = ["**/*.go", "go.mod"]
With Selective Deployments, you can choose to deploy only specific components without modifying the source code. For this example, we’ll deploy just the hello component.
Note that if you had an Spin application with more than two components, you could choose to deploy multiple components selectively.
To Selectively Deploy, we first need to turn our application into a SpinApp Custom Resource with the spin kube scaffold command, using the optional --component field to specify which component we’d like to deploy:
spin kube scaffold --from ghcr.io/spinkube/spin-operator/salutations:20241105-223428-g4da3171 --component hello --replicas 1 --out spinapp.yaml
Now if we take a look at our spinapp.yaml, we should see that only the hello component will be deployed via Selective Deployments:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: salutations
spec:
image: "ghcr.io/spinkube/spin-operator/salutations:20241105-223428-g4da3171"
executor: containerd-shim-spin
replicas: 1
components:
- hello
Run a Selective Deployment
Now you can deploy your app using kubectl as you normally would:
# Deploy the spinapp.yaml using kubectl
kubectl apply -f spinapp.yaml
spinapp.core.spinkube.dev/salutations created
We can test that only our hello component is running by port-forwarding its service.
kubectl port-forward svc/salutations 8083:80
Now let’s call the /hi route in a seperate terminal:
If the hello component is running correctly, we should see a response of “Hello Fermyon!”:
Next, let’s try the /bye route. This should return nothing, confirming that only the hello component was deployed:
There you have it! You selectively deployed a subset of your Spin application to SpinKube with no modifications to your source code. This approach lets you easily deploy only the components you need, which can improve efficiency in environments where only specific services are required.
3.2 - Packaging and deploying apps
Learn how to package and distribute Spin Apps using either public or private OCI compliant registries.
This article explains how Spin Apps are packaged and distributed via both public and private
registries. You will learn how to:
- Package and distribute Spin Apps
- Deploy Spin Apps
- Scaffold Kubernetes Manifests for Spin Apps
- Use private registries that require authentication
Prerequisites
For this tutorial in particular, you need
Creating a new Spin App
You use the spin CLI, to create a new Spin App. The spin CLI provides different templates, which
you can use to quickly create different kinds of Spin Apps. For demonstration purposes, you will use
the http-go template to create a simple Spin App.
# Create a new Spin App using the http-go template
spin new --accept-defaults -t http-go hello-spin
# Navigate into the hello-spin directory
cd hello-spin
The spin CLI created all necessary files within hello-spin. Besides the Spin Manifest
(spin.toml), you can find the actual implementation of the app in main.go:
package main
import (
"fmt"
"net/http"
spinhttp "github.com/fermyon/spin/sdk/go/v2/http"
)
func init() {
spinhttp.Handle(func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/plain")
fmt.Fprintln(w, "Hello Fermyon!")
})
}
func main() {}
This implementation will respond to any incoming HTTP request, and return an HTTP response with a
status code of 200 (Ok) and send Hello Fermyon as the response body.
You can test the app on your local machine by invoking the spin up command from within the
hello-spin folder.
Packaging and Distributing Spin Apps
Spin Apps are packaged and distributed as OCI artifacts. By leveraging OCI artifacts, Spin Apps can
be distributed using any registry that implements the Open Container Initiative Distribution
Specification (a.k.a. “OCI Distribution
Spec”).
The spin CLI simplifies packaging and distribution of Spin Apps and provides an atomic command for
this (spin registry push). You can package and distribute the hello-spin app that you created as
part of the previous section like this:
# Package and Distribute the hello-spin app
spin registry push --build ttl.sh/hello-spin:24h
It is a good practice to add the --build flag to spin registry push. It prevents you from
accidentally pushing an outdated version of your Spin App to your registry of choice.
Deploying Spin Apps
To deploy Spin Apps to a Kubernetes cluster which has Spin Operator running, you use the kube
plugin for spin. Use the spin kube deploy command as shown here to deploy the hello-spin app
to your Kubernetes cluster:
# Deploy the hello-spin app to your Kubernetes Cluster
spin kube deploy --from ttl.sh/hello-spin:24h
spinapp.core.spinkube.dev/hello-spin created
You can deploy a subset of components in your Spin Application using Selective Deployments.
Scaffolding Spin Apps
In the previous section, you deployed the hello-spin app using the spin kube deploy command.
Although this is handy, you may want to inspect, or alter the Kubernetes manifests before applying
them. You use the spin kube scaffold command to generate Kubernetes manifests:
spin kube scaffold --from ttl.sh/hello-spin:24h
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: hello-spin
spec:
image: "ttl.sh/hello-spin:24h"
replicas: 2
By default, the command will print all Kubernetes manifests to STDOUT. Alternatively, you can
specify the out argument to store the manifests to a file:
# Scaffold manifests to spinapp.yaml
spin kube scaffold --from ttl.sh/hello-spin:24h \
--out spinapp.yaml
# Print contents of spinapp.yaml
cat spinapp.yaml
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: hello-spin
spec:
image: "ttl.sh/hello-spin:24h"
replicas: 2
You can then deploy the Spin App by applying the manifest with the kubectl CLI:
kubectl apply -f spinapp.yaml
Distributing and Deploying Spin Apps via private registries
It is quite common to distribute Spin Apps through private registries that require some sort of
authentication. To publish a Spin App to a private registry, you have to authenticate using the
spin registry login command.
For demonstration purposes, you will now distribute the Spin App via GitHub Container Registry
(GHCR). You can follow this guide by
GitHub
to create a new personal access token (PAT), which is required for authentication.
# Store PAT and GitHub username as environment variables
export GH_PAT=YOUR_TOKEN
export GH_USER=YOUR_GITHUB_USERNAME
# Authenticate spin CLI with GHCR
echo $GH_PAT | spin registry login ghcr.io -u $GH_USER --password-stdin
Successfully logged in as YOUR_GITHUB_USERNAME to registry ghcr.io
Once authentication succeeded, you can use spin registry push to push your Spin App to GHCR:
# Push hello-spin to GHCR
spin registry push --build ghcr.io/$GH_USER/hello-spin:0.0.1
Pushing app to the Registry...
Pushed with digest sha256:1611d51b296574f74b99df1391e2dc65f210e9ea695fbbce34d770ecfcfba581
In Kubernetes you store authentication information as secret of type docker-registry. The
following snippet shows how to create such a secret with kubectl leveraging the environment
variables, you specified in the previous section:
# Create Secret in Kubernetes
kubectl create secret docker-registry ghcr \
--docker-server ghcr.io \
--docker-username $GH_USER \
--docker-password $CR_PAT
secret/ghcr created
Scaffold the necessary SpinApp Custom Resource (CR) using spin kube scaffold:
# Scaffold the SpinApp manifest
spin kube scaffold --from ghcr.io/$GH_USER/hello-spin:0.0.1 \
--out spinapp.yaml
Before deploying the manifest with kubectl, update spinapp.yaml and link the ghcr secret you
previously created using the imagePullSecrets property. Your SpinApp manifest should look like
this:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: hello-spin
spec:
image: ghcr.io/$GH_USER/hello-spin:0.0.1
imagePullSecrets:
- name: ghcr
replicas: 2
executor: containerd-shim-spin
$GH_USER should match the actual username provided while running through the previous sections
of this article
Finally, you can deploy the app using kubectl apply:
# Deploy the spinapp.yaml using kubectl
kubectl apply -f spinapp.yaml
spinapp.core.spinkube.dev/hello-spin created
3.3 - Making HTTPS Requests
Configure Spin Apps to allow HTTPS requests.
To enable HTTPS requests, the executor must be configured to use certificates. SpinKube can be configured to use either default or custom certificates.
If you make a request without properly configured certificates, you’ll encounter an error message that reads: error trying to connect: unexpected EOF (unable to get local issuer certificate).
Using default certificates
SpinKube can generate a default CA certificate bundle by setting installDefaultCACerts to true. This creates a secret named spin-ca populated with curl’s default bundle. You can specify a custom secret name by setting caCertSecret.
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinAppExecutor
metadata:
name: containerd-shim-spin
spec:
createDeployment: true
deploymentConfig:
runtimeClassName: wasmtime-spin-v2
installDefaultCACerts: true
Apply the executor using kubectl:
kubectl apply -f myexecutor.yaml
Using custom certificates
Create a secret from your certificate file:
kubectl create secret generic my-custom-ca --from-file=ca-certificates.crt
Configure the executor to use the custom certificate secret:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinAppExecutor
metadata:
name: containerd-shim-spin
spec:
createDeployment: true
deploymentConfig:
runtimeClassName: wasmtime-spin-v2
caCertSecret: my-custom-ca
Apply the executor using kubectl:
kubectl apply -f myexecutor.yaml
3.4 - Assigning variables
Configure Spin Apps using values from Kubernetes ConfigMaps and Secrets.
By using variables, you can alter application behavior without recompiling your SpinApp. When
running in Kubernetes, you can either provide constant values for variables, or reference them from
Kubernetes primitives such as ConfigMaps and Secrets. This tutorial guides your through the
process of assigning variables to your SpinApp.
Note: If you’d like to learn how to configure your application with an external variable provider
like Vault or Azure Key
Vault, see the External Variable Provider
guide
Build and Store SpinApp in an OCI Registry
We’re going to build the SpinApp and store it inside of a ttl.sh registry. Move
into the
apps/variable-explorer
directory and build the SpinApp we’ve provided:
# Build and publish the sample app
cd apps/variable-explorer
spin build
spin registry push ttl.sh/variable-explorer:1h
Note that the tag at the end of ttl.sh/variable-explorer:1h
indicates how long the image will last e.g. 1h (1 hour). The maximum is 24h and you will need to
repush if ttl exceeds 24 hours.
For demonstration purposes, we use the variable
explorer sample app. It
reads three different variables (log_level, platform_name and db_password) and prints their
values to the STDOUT stream as shown in the following snippet:
let log_level = variables::get("log_level")?;
let platform_name = variables::get("platform_name")?;
let db_password = variables::get("db_password")?;
println!("# Log Level: {}", log_level);
println!("# Platform name: {}", platform_name);
println!("# DB Password: {}", db_password);
Those variables are defined as part of the Spin manifest (spin.toml), and access to them is
granted to the variable-explorer component:
[variables]
log_level = { default = "WARN" }
platform_name = { default = "Fermyon Cloud" }
db_password = { required = true }
[component.variable-explorer.variables]
log_level = "{{ log_level }}"
platform_name = "{{ platform_name }}"
db_password = "{{ db_password }}"
For further reading on defining variables in the Spin manifest, see the Spin Application Manifest
Reference.
Configuration data in Kubernetes
In Kubernetes, you use ConfigMaps for storing non-sensitive, and Secrets for storing sensitive
configuration data. The deployment manifest (config/samples/variable-explorer.yaml) contains
specifications for both a ConfigMap and a Secret:
kind: ConfigMap
apiVersion: v1
metadata:
name: spinapp-cfg
data:
logLevel: INFO
---
kind: Secret
apiVersion: v1
metadata:
name: spinapp-secret
data:
password: c2VjcmV0X3NhdWNlCg==
Assigning variables to a SpinApp
When creating a SpinApp, you can choose from different approaches for specifying variables:
- Providing constant values
- Loading configuration values from ConfigMaps
- Loading configuration values from Secrets
The SpinApp specification contains the variables array, that you use for specifying variables
(See kubectl explain spinapp.spec.variables).
The deployment manifest (config/samples/variable-explorer.yaml) specifies a static value for
platform_name. The value of log_level is read from the ConfigMap called spinapp-cfg, and the
db_password is read from the Secret called spinapp-secret:
kind: SpinApp
apiVersion: core.spinkube.dev/v1alpha1
metadata:
name: variable-explorer
spec:
replicas: 1
image: ttl.sh/variable-explorer:1h
executor: containerd-shim-spin
variables:
- name: platform_name
value: Kubernetes
- name: log_level
valueFrom:
configMapKeyRef:
name: spinapp-cfg
key: logLevel
optional: true
- name: db_password
valueFrom:
secretKeyRef:
name: spinapp-secret
key: password
optional: false
As the deployment manifest outlines, you can use the optional property - as you would do when
specifying environment variables for a regular Kubernetes Pod - to control if Kubernetes should
prevent starting the SpinApp, if the referenced configuration source does not exist.
You can deploy all resources by executing the following command:
kubectl apply -f config/samples/variable-explorer.yaml
configmap/spinapp-cfg created
secret/spinapp-secret created
spinapp.core.spinkube.dev/variable-explorer created
Inspecting runtime logs of your SpinApp
To verify that all variables are passed correctly to the SpinApp, you can configure port forwarding
from your local machine to the corresponding Kubernetes Service:
kubectl port-forward services/variable-explorer 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
When port forwarding is established, you can send an HTTP request to the variable-explorer from
within an additional terminal session:
curl http://localhost:8080
Hello from Kubernetes
Finally, you can use kubectl logs to see all logs produced by the variable-explorer at runtime:
kubectl logs -l core.spinkube.dev/app-name=variable-explorer
# Log Level: INFO
# Platform Name: Kubernetes
# DB Password: secret_sauce
3.5 - External Variable Providers
Configure external variable providers for your Spin App.
In the Assigning Variables guide, you learned how to configure variables
on the SpinApp via its variables section,
either by supplying values in-line or via a Kubernetes ConfigMap or Secret.
You can also utilize an external service like Vault or Azure Key
Vault to provide variable values for your
application. This guide will show you how to use and configure both services in tandem with
corresponding sample applications.
Prerequisites
To follow along with this tutorial, you’ll need:
Supported providers
Spin currently supports Vault and Azure Key Vault as
external variable providers. Configuration is supplied to the application via a Runtime
Configuration
file.
In SpinKube, this configuration file can be supplied in the form of a Kubernetes secret and linked
to a SpinApp via its
runtimeConfig.loadFromSecret
section.
Note: loadFromSecret takes precedence over any other runtimeConfig configuration. Thus, all
runtime configuration must be contained in the Kubernetes secret, including
SQLite, Key
Value and
LLM options that might otherwise be
specified via their dedicated specs.
Let’s look at examples utilizing specific provider configuration next.
Vault provider
Vault is a popular choice for storing secrets and serving as a secure
key-value store.
This guide assumes you have:
Build and publish the Spin application
We’ll use the variable explorer
app to test this
integration.
First, clone the repository locally and navigate to the variable-explorer directory:
git clone git@github.com:spinkube/spin-operator.git
cd apps/variable-explorer
Now, build and push the application to a registry you have access to. Here we’ll use
ttl.sh:
spin build
spin registry push ttl.sh/variable-explorer:1h
Create the runtime-config.toml file
Here’s a sample runtime-config.toml file containing Vault provider configuration:
[[config_provider]]
type = "vault"
url = "https://my-vault-server:8200"
token = "my_token"
mount = "admin/secret"
To use this sample, you’ll want to update the url and token fields with values applicable to
your Vault cluster. The mount value will depend on the Vault namespace and kv-v2 secrets engine
name. In this sample, the namespace is admin and the engine is named secret, eg by running
vault secrets enable --path=secret kv-v2.
Create the secrets in Vault
Create the log_level, platform_name and db_password secrets used by the variable-explorer
application in Vault:
vault kv put secret/log_level value=INFO
vault kv put secret/platform_name value=Kubernetes
vault kv put secret/db_password value=secret_sauce
Create the SpinApp and Secret
Next, scaffold the SpinApp and Secret resource (containing the runtime-config.toml data) together
in one go via the kube plugin:
spin kube scaffold -f ttl.sh/variable-explorer:1h -c runtime-config.toml -o scaffold.yaml
Deploy the application
kubectl apply -f scaffold.yaml
Test the application
You are now ready to test the application and verify that all variables are passed correctly to the
SpinApp from the Vault provider.
Configure port forwarding from your local machine to the corresponding Kubernetes Service:
kubectl port-forward services/variable-explorer 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
When port forwarding is established, you can send an HTTP request to the variable-explorer from
within an additional terminal session:
curl http://localhost:8080
Hello from Kubernetes
Finally, you can use kubectl logs to see all logs produced by the variable-explorer at runtime:
kubectl logs -l core.spinkube.dev/app-name=variable-explorer
# Log Level: INFO
# Platform Name: Kubernetes
# DB Password: secret_sauce
Azure Key Vault provider
Azure Key Vault is a secure secret store for
distributed applications hosted on the Azure platform.
This guide assumes you have:
Build and publish the Spin application
We’ll use the Azure Key Vault
Provider
sample application for this exercise.
First, clone the repository locally and navigate to the azure-key-vault-provider directory:
git clone git@github.com:fermyon/enterprise-architectures-and-patterns.git
cd enterprise-architectures-and-patterns/application-variable-providers/azure-key-vault-provider
Now, build and push the application to a registry you have access to. Here we’ll use
ttl.sh:
spin build
spin registry push ttl.sh/azure-key-vault-provider:1h
The next steps will guide you in creating and configuring an Azure Key Vault and populating the
runtime configuration file with connection credentials.
Deploy Azure Key Vault
# Variable Definition
KV_NAME=spinkube-keyvault
LOCATION=westus2
RG_NAME=rg-spinkube-keyvault
# Create Azure Resource Group and Azure Key Vault
az group create -n $RG_NAME -l $LOCATION
az keyvault create -n $KV_NAME \
-g $RG_NAME \
-l $LOCATION \
--enable-rbac-authorization true
# Grab the Azure Resource Identifier of the Azure Key Vault instance
KV_SCOPE=$(az keyvault show -n $KV_NAME -g $RG_NAME -otsv --query "id")
Add a Secret to the Azure Key Vault instance
# Grab the ID of the currently signed in user in Azure CLI
CURRENT_USER_ID=$(az ad signed-in-user show -otsv --query "id")
# Make the currently signed in user a Key Vault Secrets Officer
# on the scope of the new Azure Key Vault instance
az role assignment create --assignee $CURRENT_USER_ID \
--role "Key Vault Secrets Officer" \
--scope $KV_SCOPE
# Create a test secret called 'secret` in the Azure Key Vault instance
az keyvault secret set -n secret --vault-name $KV_NAME --value secret_value -o none
Create a Service Principal and Role Assignment for Spin
SP_NAME=sp-spinkube-keyvault
SP=$(az ad sp create-for-rbac -n $SP_NAME -ojson)
CLIENT_ID=$(echo $SP | jq -r '.appId')
CLIENT_SECRET=$(echo $SP | jq -r '.password')
TENANT_ID=$(echo $SP | jq -r '.tenant')
az role assignment create --assignee $CLIENT_ID \
--role "Key Vault Secrets User" \
--scope $KV_SCOPE
Create the runtime-config.toml file
Create a runtime-config.toml file with the following contents, substituting in the values for
KV_NAME, CLIENT_ID, CLIENT_SECRET and TENANT_ID from the previous steps.
[[config_provider]]
type = "azure_key_vault"
vault_url = "https://<$KV_NAME>.vault.azure.net/"
client_id = "<$CLIENT_ID>"
client_secret = "<$CLIENT_SECRET>"
tenant_id = "<$TENANT_ID>"
authority_host = "AzurePublicCloud"
Create the SpinApp and Secret
Scaffold the SpinApp and Secret resource (containing the runtime-config.toml data) together in one
go via the kube plugin:
spin kube scaffold -f ttl.sh/azure-key-vault-provider:1h -c runtime-config.toml -o scaffold.yaml
Deploy the application
kubectl apply -f scaffold.yaml
Test the application
Now you are ready to test the application and verify that the secret resolves its value from Azure
Key Vault.
Configure port forwarding from your local machine to the corresponding Kubernetes Service:
kubectl port-forward services/azure-key-vault-provider 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
When port forwarding is established, you can send an HTTP request to the azure-key-vault-provider
app from within an additional terminal session:
curl http://localhost:8080
Loaded secret from Azure Key Vault: secret_value
3.6 - Connecting to your app
Learn how to connect to your application.
This topic guide shows you how to connect to your application deployed to SpinKube, including how to
use port-forwarding for local development, or Ingress rules for a production setup.
Run the sample application
Let’s deploy a sample application to your Kubernetes cluster. We will use this application
throughout the tutorial to demonstrate how to connect to it.
Refer to the quickstart guide if you haven’t set up a Kubernetes cluster
yet.
kubectl apply -f https://raw.githubusercontent.com/spinkube/spin-operator/main/config/samples/simple.yaml
When SpinKube deploys the application, it creates a Kubernetes Service that exposes the application
to the cluster. You can check the status of the deployment with the following command:
You should see a service named simple-spinapp with a type of ClusterIP. This means that the
service is only accessible from within the cluster.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
simple-spinapp ClusterIP 10.43.152.184 <none> 80/TCP 1m
We will use this service to connect to your application.
Port forwarding
This option is useful for debugging and development. It allows you to forward a local port to the
service.
Forward port 8083 to the service so that it can be reached from your computer:
kubectl port-forward svc/simple-spinapp 8083:80
You should be able to reach it from your browser at http://localhost:8083:
curl http://localhost:8083
You should see a message like “Hello world from Spin!”.
This is one of the simplest ways to test your application. However, it is not suitable for
production use. The next section will show you how to expose your application to the internet using
an Ingress controller.
Ingress
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster.
Traffic routing is controlled by rules defined on the Ingress resource.
Here is a simple example where an Ingress sends all its traffic to one Service:

(source: Kubernetes
documentation)
An Ingress may be configured to give applications externally-reachable URLs, load balance traffic,
terminate SSL / TLS, and offer name-based virtual hosting. An Ingress controller is responsible for
fulfilling the Ingress, usually with a load balancer, though it may also configure your edge router
or additional frontends to help handle the traffic.
Prerequisites
You must have an Ingress
controller to satisfy
an Ingress rule. Creating an Ingress rule without a controller has no effect.
Ideally, all Ingress controllers should fit the reference specification. In reality, the various
Ingress controllers operate slightly differently. Make sure you review your Ingress controller’s
documentation to understand the specifics of how it works.
ingress-nginx is a popular Ingress controller,
so we will use it in this tutorial:
helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace
Wait for the ingress controller to be ready:
kubectl wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=120s
Check the Ingress controller’s external IP address
If your Kubernetes cluster is a “real” cluster that supports services of type LoadBalancer, it
will have allocated an external IP address or FQDN to the ingress controller.
Check the IP address or FQDN with the following command:
kubectl get service ingress-nginx-controller --namespace=ingress-nginx
It will be the EXTERNAL-IP field. If that field shows <pending>, this means that your Kubernetes
cluster wasn’t able to provision the load balancer. Generally, this is because it doesn’t support
services of type LoadBalancer.
Once you have the external IP address (or FQDN), set up a DNS record pointing to it. Refer to your
DNS provider’s documentation on how to add a new DNS record to your domain.
You will want to create an A record that points to the external IP address. If your external IP
address is <EXTERNAL-IP>, you would create a record like this:
A myapp.spinkube.local <EXTERNAL-IP>
Once you’ve added a DNS record to your domain and it has propagated, proceed to create an ingress
resource.
Create an Ingress resource
Create an Ingress resource that routes traffic to the simple-spinapp service. The following
example assumes that you have set up a DNS record for myapp.spinkube.local:
kubectl create ingress simple-spinapp --class=nginx --rule="myapp.spinkube.local/*=simple-spinapp:80"
A couple notes about the above command:
simple-spinapp is the name of the Ingress resource.myapp.spinkube.local is the hostname that the Ingress will route traffic to. This is the DNS
record you set up earlier.simple-spinapp:80 is the Service that SpinKube created for us. The application listens for
requests on port 80.
Assuming DNS has propagated correctly, you should see a message like “Hello world from Spin!” when
you connect to http://myapp.spinkube.local/.
Congratulations, you are serving a public website hosted on a Kubernetes cluster! 🎉
Connecting with kubectl port-forward
This is a quick way to test your Ingress setup without setting up DNS records or on clusters without
support for services of type LoadBalancer.
Open a new terminal and forward a port from localhost port 8080 to the Ingress controller:
kubectl port-forward --namespace=ingress-nginx service/ingress-nginx-controller 8080:80
Then, in another terminal, test the Ingress setup:
curl --resolve myapp.spinkube.local:8080:127.0.0.1 http://myapp.spinkube.local:8080/hello
You should see a message like “Hello world from Spin!”.
If you want to see your app running in the browser, update your /etc/hosts file to resolve
requests from myapp.spinkube.local to the ingress controller:
127.0.0.1 myapp.spinkube.local
3.7 - Monitoring your app
How to view telemetry data from your Spin apps running in SpinKube.
This topic guide shows you how to configure SpinKube so your Spin apps export observability data. This data will export to an OpenTelemetry collector which will send it to Jaeger.
Prerequisites
Please ensure you have the following tools installed before continuing:
About OpenTelemetry Collector
From the OpenTelemetry documentation:
The OpenTelemetry Collector offers a vendor-agnostic implementation of how to receive, process and export telemetry data. It removes the need to run, operate, and maintain multiple agents/collectors. This works with improved scalability and supports open source observability data formats (e.g. Jaeger, Prometheus, Fluent Bit, etc.) sending to one or more open source or commercial backends.
In our case, the OpenTelemetry collector serves as a single endpoint to receive and route telemetry data, letting us to monitor metrics, traces, and logs via our preferred UIs.
About Jaeger
From the Jaeger documentation:
Jaeger is a distributed tracing platform released as open source by Uber Technologies. With Jaeger you can: Monitor and troubleshoot distributed workflows, Identify performance bottlenecks, Track down root causes, Analyze service dependencies
Here, we have the OpenTelemetry collector send the trace data to Jaeger.
Deploy OpenTelemetry Collector
First, add the OpenTelemetry collector Helm repository:
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
Next, deploy the OpenTelemetry collector to your cluster:
helm upgrade --install otel-collector open-telemetry/opentelemetry-collector \
--set image.repository="otel/opentelemetry-collector-k8s" \
--set nameOverride=otel-collector \
--set mode=deployment \
--set config.exporters.otlp.endpoint=http://jaeger-collector.default.svc.cluster.local:4317 \
--set config.exporters.otlp.tls.insecure=true \
--set config.service.pipelines.traces.exporters\[0\]=otlp \
--set config.service.pipelines.traces.processors\[0\]=batch \
--set config.service.pipelines.traces.receivers\[0\]=otlp \
--set config.service.pipelines.traces.receivers\[1\]=jaeger
Deploy Jaeger
Next, add the Jaeger Helm repository:
helm repo add jaegertracing https://jaegertracing.github.io/helm-charts
helm repo update
Then, deploy Jaeger to your cluster:
helm upgrade --install jaeger jaegertracing/jaeger \
--set provisionDataStore.cassandra=false \
--set allInOne.enabled=true \
--set agent.enabled=false \
--set collector.enabled=false \
--set query.enabled=false \
--set storage.type=memory
The SpinAppExecutor resource determines how Spin applications are deployed in the cluster. The following configuration will ensure that any SpinApp resource using this executor will send telemetry data to the OpenTelemetry collector. To see a comprehensive list of OTel options for the SpinAppExecutor, see the API reference.
Create a file called executor.yaml with the following content:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinAppExecutor
metadata:
name: otel-shim-executor
spec:
createDeployment: true
deploymentConfig:
runtimeClassName: wasmtime-spin-v2
installDefaultCACerts: true
otel:
exporter_otlp_endpoint: http://otel-collector.default.svc.cluster.local:4318
To deploy the executor, run:
kubectl apply -f executor.yaml
Deploy a Spin app to observe
With everything in place, we can now deploy a SpinApp resource that uses the executor otel-shim-executor.
Create a file called app.yaml with the following content:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: otel-spinapp
spec:
image: ghcr.io/spinkube/spin-operator/cpu-load-gen:20240311-163328-g1121986
executor: otel-shim-executor
replicas: 1
Deploy the app by running:
kubectl apply -f app.yaml
Congratulations! You now have a Spin app exporting telemetry data.
Next, we need to generate telemetry data for the Spin app to export. Use the below command to port-forward the Spin app:
kubectl port-forward svc/otel-spinapp 3000:80
In a new terminal window, execute a curl request:
The request will take a couple of moments to run, but once it’s done, you should see an output similar to this:
fib(43) = 433494437
Interact with Jaeger
To view the traces in Jaeger, use the following port-forward command:
kubectl port-forward svc/jaeger-query 16686:16686
Then, open your browser and navigate to localhost:16686 to interact with Jaeger’s UI.
3.8 - Using a key value store
Connect your Spin App to a key value store
Spin applications can utilize a standardized API for persisting data in a key value
store. The default key value store in
Spin is an SQLite database, which is great for quickly utilizing non-relational local storage
without any infrastructure set-up. However, this solution may not be preferable for an app running
in the context of SpinKube, where apps are often scaled beyond just one replica.
Thankfully, Spin supports configuring an application with an external key value
provider.
External providers include Redis or Valkey and Azure
Cosmos DB.
Prerequisites
To follow along with this tutorial, you’ll need:
Build and publish the Spin application
For this tutorial, we’ll use a Spin key/value
application written with the
Go SDK. The application serves a CRUD (Create, Read, Update, Delete) API for managing key/value
pairs.
First, clone the repository locally and navigate to the examples/key-value directory:
git clone git@github.com:fermyon/spin-go-sdk.git
cd examples/key-value
Now, build and push the application to a registry you have access to. Here we’ll use
ttl.sh:
export IMAGE_NAME=ttl.sh/$(uuidgen):1h
spin build
spin registry push ${IMAGE_NAME}
Since we have access to a Kubernetes cluster already running SpinKube, we’ll choose
Valkey for our key value provider and install this provider via Bitnami’s
Valkey Helm chart. Valkey is swappable
for Redis in Spin, though note we do need to supply a URL using the redis:// protocol rather than
valkey://.
helm install valkey --namespace valkey --create-namespace oci://registry-1.docker.io/bitnamicharts/valkey
As mentioned in the notes shown after successful installation, be sure to capture the valkey
password for use later:
export VALKEY_PASSWORD=$(kubectl get secret --namespace valkey valkey -o jsonpath="{.data.valkey-password}" | base64 -d)
Create a Kubernetes Secret for the Valkey URL
The runtime configuration will require the Valkey URL so that it can connect to this provider. As
this URL contains the sensitive password string, we will create it as a Secret resource in
Kubernetes:
kubectl create secret generic kv-secret --from-literal=valkey-url="redis://:${VALKEY_PASSWORD}@valkey-master.valkey.svc.cluster.local:6379"
Prepare the SpinApp manifest
You’re now ready to assemble the SpinApp custom resource manifest for this application.
- All of the key value config is set under
spec.runtimeConfig.keyValueStores. See the
keyValueStores reference guide for more details. - Here we configure the
default store to use the redis provider type and under options supply
the Valkey URL (via its Kubernetes secret)
Plug the $IMAGE_NAME and $DB_URL values into the manifest below and save as spinapp.yaml:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: kv-app
spec:
image: "$IMAGE_NAME"
replicas: 1
executor: containerd-shim-spin
runtimeConfig:
keyValueStores:
- name: "default"
type: "redis"
options:
- name: "url"
valueFrom:
secretKeyRef:
name: "kv-secret"
key: "valkey-url"
Create the SpinApp
Apply the resource manifest to your Kubernetes cluster:
kubectl apply -f spinapp.yaml
The Spin Operator will handle the creation of the underlying Kubernetes resources on your behalf.
Test the application
Now you are ready to test the application and verify connectivity and key value storage to the
configured provider.
Configure port forwarding from your local machine to the corresponding Kubernetes Service:
kubectl port-forward services/kv-app 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
When port forwarding is established, you can send HTTP requests to the application from within an
additional terminal session. Here are a few examples to get you started.
Create a test key with value ok!:
$ curl -i -X POST -d "ok!" localhost:8080/test
HTTP/1.1 200 OK
content-length: 0
date: Mon, 29 Jul 2024 19:58:14 GMT
Get the value for the test key:
$ curl -i -X GET localhost:8080/test
HTTP/1.1 200 OK
content-length: 3
date: Mon, 29 Jul 2024 19:58:39 GMT
ok!
Delete the value for the test key:
$ curl -i -X DELETE localhost:8080/test
HTTP/1.1 200 OK
content-length: 0
date: Mon, 29 Jul 2024 19:59:18 GMT
Attempt to get the value for the test key:
$ curl -i -X GET localhost:8080/test
HTTP/1.1 500 Internal Server Error
content-type: text/plain; charset=utf-8
x-content-type-options: nosniff
content-length: 12
date: Mon, 29 Jul 2024 19:59:44 GMT
no such key
3.9 - Connecting to a SQLite database
Connect your Spin App to an external SQLite database
Spin applications can utilize a standardized API for persisting data in a SQLite
database. A default database is created by
the Spin runtime on the local filesystem, which is great for getting an application up and running.
However, this on-disk solution may not be preferable for an app running in the context of SpinKube,
where apps are often scaled beyond just one replica.
Thankfully, Spin supports configuring an application with an external SQLite database provider via
runtime
configuration.
External providers include any libSQL databases that can be accessed over
HTTPS.
Prerequisites
To follow along with this tutorial, you’ll need:
Build and publish the Spin application
For this tutorial, we’ll use the HTTP CRUD Go
SQLite
sample application. It is a Go-based app implementing CRUD (Create, Read, Update, Delete) operations
via the SQLite API.
First, clone the repository locally and navigate to the http-crud-go-sqlite directory:
git clone git@github.com:fermyon/enterprise-architectures-and-patterns.git
cd enterprise-architectures-and-patterns/http-crud-go-sqlite
Now, build and push the application to a registry you have access to. Here we’ll use
ttl.sh:
export IMAGE_NAME=ttl.sh/$(uuidgen):1h
spin build
spin registry push ${IMAGE_NAME}
Create a LibSQL database
If you don’t already have a LibSQL database that can be used over HTTPS, you can follow along as we
set one up via Turso.
Before proceeding, install the turso CLI and sign up for an
account, if you haven’t done so already.
Create a new database and save its HTTP URL:
turso db create spinkube
export DB_URL=$(turso db show spinkube --http-url)
Next, create an auth token for this database:
export DB_TOKEN=$(turso db tokens create spinkube)
Create a Kubernetes Secret for the database token
The database token is a sensitive value and thus should be created as a Secret resource in
Kubernetes:
kubectl create secret generic turso-auth --from-literal=db-token="${DB_TOKEN}"
Prepare the SpinApp manifest
You’re now ready to assemble the SpinApp custom resource manifest.
- Note the
image value uses the reference you published above. - All of the SQLite database config is set under
spec.runtimeConfig.sqliteDatabases. See the
sqliteDatabases reference guide for more details. - Here we configure the
default database to use the libsql provider type and under options
supply the database URL and auth token (via its Kubernetes secret)
Plug the $IMAGE_NAME and $DB_URL values into the manifest below and save as spinapp.yaml:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: http-crud-go-sqlite
spec:
image: "$IMAGE_NAME"
replicas: 1
executor: containerd-shim-spin
runtimeConfig:
sqliteDatabases:
- name: "default"
type: "libsql"
options:
- name: "url"
value: "$DB_URL"
- name: "token"
valueFrom:
secretKeyRef:
name: "turso-auth"
key: "db-token"
Create the SpinApp
Apply the resource manifest to your Kubernetes cluster:
kubectl apply -f spinapp.yaml
The Spin Operator will handle the creation of the underlying Kubernetes resources on your behalf.
Test the application
Now you are ready to test the application and verify connectivity and data storage to the configured
SQLite database.
Configure port forwarding from your local machine to the corresponding Kubernetes Service:
kubectl port-forward services/http-crud-go-sqlite 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
When port forwarding is established, you can send HTTP requests to the http-crud-go-sqlite app from
within an additional terminal session. Here are a few examples to get you started.
Get current items:
$ curl -X GET http://localhost:8080/items
[
{
"id": "8b933c84-ee60-45a1-848d-428ad3259e2b",
"name": "Full Self Driving (FSD)",
"active": true
},
{
"id": "d660b9b2-0406-46d6-9efe-b40b4cca59fc",
"name": "Sentry Mode",
"active": true
}
]
Create a new item:
$ curl -X POST -d '{"name":"Engage Thrusters","active":true}' localhost:8080/items
{
"id": "a5efaa73-a4ac-4ffc-9c5c-61c5740e2d9f",
"name": "Engage Thrusters",
"active": true
}
Get items and see the newly added item:
$ curl -X GET http://localhost:8080/items
[
{
"id": "8b933c84-ee60-45a1-848d-428ad3259e2b",
"name": "Full Self Driving (FSD)",
"active": true
},
{
"id": "d660b9b2-0406-46d6-9efe-b40b4cca59fc",
"name": "Sentry Mode",
"active": true
},
{
"id": "a5efaa73-a4ac-4ffc-9c5c-61c5740e2d9f",
"name": "Engage Thrusters",
"active": true
}
]
3.10 - Autoscaling your apps
Guides on autoscaling your applications with SpinKube.
3.10.1 - Using the `spin kube` plugin
A tutorial to show how autoscaler support can be enabled via the spin kube command.
Horizontal autoscaling support
In Kubernetes, a horizontal autoscaler automatically updates a workload resource (such as a
Deployment or StatefulSet) with the aim of automatically scaling the workload to match demand.
Horizontal scaling means that the response to increased load is to deploy more resources. This is
different from vertical scaling, which for Kubernetes would mean assigning more memory or CPU to the
resources that are already running for the workload.
If the load decreases, and the number of resources is above the configured minimum, a horizontal
autoscaler would instruct the workload resource (the Deployment, StatefulSet, or other similar
resource) to scale back down.
The Kubernetes plugin for Spin includes autoscaler support, which allows you to tell Kubernetes when
to scale your Spin application up or down based on demand. This tutorial will show you how to enable
autoscaler support via the spin kube scaffold command.
Prerequisites
Regardless of what type of autoscaling is used, you must determine how you want your application to
scale by answering the following questions:
- Do you want your application to scale based upon system metrics (CPU and memory utilization) or
based upon events (like messages in a queue or rows in a database)?
- If you application scales based on system metrics, how much CPU and memory each instance does
your application need to operate?
Choosing an autoscaler
The Kubernetes plugin for Spin supports two types of autoscalers: Horizontal Pod Autoscaler (HPA)
and Kubernetes Event-driven Autoscaling (KEDA). The choice of autoscaler depends on the requirements
of your application.
Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaler (HPA) scales Kubernetes pods based on CPU or memory utilization. This HPA
scaling can be implemented via the Kubernetes plugin for Spin by setting the --autoscaler hpa
option. This page deals exclusively with autoscaling via the Kubernetes plugin for Spin.
spin kube scaffold --from user-name/app-name:latest --autoscaler hpa --cpu-limit 100m --memory-limit 128Mi
Horizontal Pod Autoscaling is built-in to Kubernetes and does not require the installation of a
third-party runtime. For more general information about scaling with HPA, please see the Spin
Operator’s Scaling with HPA section
Kubernetes Event-driven Autoscaling (KEDA)
Kubernetes Event-driven Autoscaling (KEDA) is an extension of Horizontal Pod Autoscaling (HPA). On
top of allowing to scale based on CPU or memory utilization, KEDA allows for scaling based on events
from various sources like messages in a queue, or the number of rows in a database.
KEDA can be enabled by setting the --autoscaler keda option:
spin kube scaffold --from user-name/app-name:latest --autoscaler keda --cpu-limit 100m --memory-limit 128Mi -replicas 1 --max-replicas 10
Using KEDA to autoscale your Spin applications requires the installation of the KEDA
runtime into your Kubernetes cluster. For more information about scaling with
KEDA in general, please see the Spin Operator’s Scaling with KEDA section
Setting min/max replicas
The --replicas and --max-replicas options can be used to set the minimum and maximum number of
replicas for your application. The --replicas option defaults to 2 and the --max-replicas option
defaults to 3.
spin kube scaffold --from user-name/app-name:latest --autoscaler hpa --cpu-limit 100m --memory-limit 128Mi -replicas 1 --max-replicas 10
Setting CPU/memory limits and CPU/memory requests
If the node where an application is running has enough of a resource available, it’s possible (and
allowed) for that application to use more resource than its resource request for that resource
specifies. However, an application is not allowed to use more than its resource limit.
For example, if you set a memory request of 256 MiB, and that application is scheduled to a node
with 8GiB of memory and no other appplications, then the application can try to use more RAM.
If you set a memory limit of 4GiB for that application, the webassembly runtime will enforce that
limit. The runtime prevents the application from using more than the configured resource limit. For
example: when a process in the application tries to consume more than the allowed amount of memory,
the webassembly runtime terminates the process that attempted the allocation with an out of memory
(OOM) error.
The --cpu-limit, --memory-limit, --cpu-request, and --memory-request options can be used to
set the CPU and memory limits and requests for your application. The --cpu-limit and
--memory-limit options are required, while the --cpu-request and --memory-request options are
optional.
It is important to note the following:
- CPU/memory requests are optional and will default to the CPU/memory limit if not set.
- CPU/memory requests must be lower than their respective CPU/memory limit.
- If you specify a limit for a resource, but do not specify any request, and no admission-time
mechanism has applied a default request for that resource, then Kubernetes copies the limit you
specified and uses it as the requested value for the resource.
spin kube scaffold --from user-name/app-name:latest --autoscaler hpa --cpu-limit 100m --memory-limit 128Mi --cpu-request 50m --memory-request 64Mi
Setting target utilization
Target utilization is the percentage of the resource that you want to be used before the autoscaler
kicks in. The autoscaler will check the current resource utilization of your application against the
target utilization and scale your application up or down based on the result.
Target utilization is based on the average resource utilization across all instances of your
application. For example, if you have 3 instances of your application, the target CPU utilization is
50%, and each application is averaging 80% CPU utilization, the autoscaler will continue to increase
the number of instances until all instances are averaging 50% CPU utilization.
To scale based on CPU utilization, use the --autoscaler-target-cpu-utilization option:
spin kube scaffold --from user-name/app-name:latest --autoscaler hpa --cpu-limit 100m --memory-limit 128Mi --autoscaler-target-cpu-utilization 50
To scale based on memory utilization, use the --autoscaler-target-memory-utilization option:
spin kube scaffold --from user-name/app-name:latest --autoscaler hpa --cpu-limit 100m --memory-limit 128Mi --autoscaler-target-memory-utilization 50
3.10.2 - Scaling Spin App With Horizontal Pod Autoscaling (HPA)
This tutorial illustrates how one can horizontally scale Spin Apps in Kubernetes using Horizontal Pod Autscaling (HPA).
Horizontal scaling, in the Kubernetes sense, means deploying more pods to meet demand (different
from vertical scaling whereby more memory and CPU resources are assigned to already running pods).
In this tutorial, we configure
HPA to dynamically
scale the instance count of our SpinApps to meet the demand.
Prerequisites
Ensure you have the following tools installed:
- Docker - for running kind
- kubectl - the Kubernetes CLI
- kind - a development Kubernetes distribution that runs on Docker
- Helm - the package manager for Kubernetes
- Bombardier - cross-platform HTTP
benchmarking CLI
We use kind to run a Kubernetes cluster locally as part of this tutorial, but you can follow these
steps to configure HPA autoscaling on your desired Kubernetes environment.
Setting Up Kubernetes Cluster
Run the following command to create a Kubernetes cluster that has the
containerd-shim-spin pre-requisites installed: If
you have a Kubernetes cluster already, or want to start with a more production ready SpinKube installation, follow the Helm installation guide instead, which include instructions for configuring the Runtime Class Manager for managing the lifecycle of the Spin containerd shim. The following kind cluster creation creates a three node cluster with containerd configuration to instruct containerd to use the Spin containerd shim for workloads scheduled with the spin runtime class. We are also exposing host port 8081 to make load testing easier in later steps.
cat <<EOF | kind create cluster --name wasm-cluster-scale --image ghcr.io/spinframework/containerd-shim-spin/kind:v0.25.0 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
containerdConfigPatches:
- |-
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin]
runtime_type = "io.containerd.spin.v2"
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin.options]
SystemdCgroup = true
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 80
hostPort: 8081
protocol: TCP
- role: worker
- role: worker
EOF
Deploying Spin Operator and its dependencies
First, you have to install cert-manager to
automatically provision and manage TLS certificates (used by Spin Operator’s admission webhook
system). For detailed installation instructions see the cert-manager
documentation.
# Install cert-manager CRDs
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.crds.yaml
# Add and update Jetstack repository
helm repo add jetstack https://charts.jetstack.io
helm repo update
# Install the cert-manager Helm chart
helm install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.20.0
Next, run the following commands to install the Spin Runtime Class and Spin Operator Custom Resource Definitions (CRDs):
Note: In a production cluster you likely want to customize the Runtime Class with a nodeSelector
that matches nodes that have the shim installed. However, in the kind example, they’re installed on
every node.
# Install the RuntimeClass
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.runtime-class.yaml
# Install the CRDs
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
Lastly, install Spin Operator using helm and the shim executor with the following commands:
# Install Spin Operator
helm install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
# Install the shim executor
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Great, now you have Spin Operator up and running on your cluster. This means you’re set to create
and deploy SpinApps later on in the tutorial.
Install an Ingress Controller
Install an ingress controller in your cluster. This example uses Traefik as the ingress controller for local routing in Kind. We are requiring that it is run on the control-plane node where the hostPort is exposed.
helm repo add traefik https://helm.traefik.io/traefik
helm repo update
helm install traefik traefik/traefik \
--namespace traefik --create-namespace \
--set deployment.kind=DaemonSet \
--set service.type=ClusterIP \
--set ports.web.hostPort=80 \
--set tolerations[0].key=node-role.kubernetes.io/control-plane \
--set tolerations[0].effect=NoSchedule \
--set tolerations[0].operator=Exists \
--set nodeSelector."kubernetes\.io/hostname"=wasm-cluster-scale-control-plane
kubectl wait --namespace traefik --for=condition=ready pod --selector=app.kubernetes.io/name=traefik --timeout=180s
Set Up Ingress for the Spin App
Use the following command to set up ingress on your Kubernetes cluster. This ensures traffic can
reach your Spin app once we’ve created it in future steps:
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
annotations:
ingress.kubernetes.io/ssl-redirect: "false"
spec:
ingressClassName: traefik
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: hpa-spinapp
port:
number: 80
EOF
Deploy Spin App and HorizontalPodAutoscaler (HPA)
Next up we’re going to deploy the Spin App we will be scaling. You can find the source code of the
Spin App in the
apps/cpu-load-gen folder of
the Spin Operator repository.
We can take a look at the SpinApp and HPA definitions in our deployment file below/. As you can see,
we have set our resources -> limits to 500m of cpu and 500Mi of memory per Spin
application and we will scale the instance count when we’ve reached a 50% utilization in cpu and
memory. We’ve also defined support a maximum
replica count of
10 and a minimum replica count of 1:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: hpa-spinapp
spec:
image: ghcr.io/spinkube/spin-operator/cpu-load-gen:20240311-163328-g1121986
enableAutoscaling: true
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 100m
memory: 400Mi
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: spinapp-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-spinapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
For more information about HPA, please visit the following links:
Below is an example of the configuration to scale resources:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: hpa-spinapp
spec:
image: ghcr.io/spinkube/spin-operator/cpu-load-gen:20240311-163328-g1121986
executor: containerd-shim-spin
enableAutoscaling: true
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 100m
memory: 400Mi
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: spinapp-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-spinapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Let’s deploy the SpinApp and the HPA instance onto our cluster (using the above .yaml
configuration). To apply the above configuration we use the following kubectl apply command:
# Install SpinApp and HPA
kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/hpa.yaml
You can see your running Spin application by running the following command:
kubectl get spinapps
NAME AGE
hpa-spinapp 92m
You can also see your HPA instance with the following command:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
spinapp-autoscaler Deployment/hpa-spinapp 6%/50% 1 10 1 97m
Please note: The Kubernetes Plugin for
Spin is a tool designed for
Kubernetes integration with the Spin command-line interface. The Kubernetes Plugin for Spin has a
scaling tutorial
that demonstrates how to use the spin kube command to tell Kubernetes when to scale your Spin
application up or down based on demand).
Generate Load to Test Autoscale
Now let’s use Bombardier to generate traffic to test how well HPA scales our SpinApp. The following
Bombardier command will attempt to establish 40 connections during a period of 3 minutes (or less).
If a request is not responded to within 5 seconds that request will timeout:
# Generate a bunch of load
bombardier -c 40 -t 5s -d 3m http://localhost:8081
To watch the load, we can run the following command to get the status of our deployment:
kubectl describe deploy hpa-spinapp
...
---
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hpa-spinapp-544c649cf4 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set hpa-spinapp-544c649cf4 to 1
Normal ScalingReplicaSet 9m45s deployment-controller Scaled up replica set hpa-spinapp-544c649cf4 to 4
Normal ScalingReplicaSet 9m30s deployment-controller Scaled up replica set hpa-spinapp-544c649cf4 to 8
Normal ScalingReplicaSet 9m15s deployment-controller Scaled up replica set hpa-spinapp-544c649cf4 to 10
3.10.3 - Scaling Spin App With Kubernetes Event-Driven Autoscaling (KEDA)
This tutorial illustrates how one can horizontally scale Spin Apps in Kubernetes using Kubernetes Event-Driven Autoscaling (KEDA).
KEDA extends Kubernetes to provide event-driven scaling capabilities, allowing it
to react to events from Kubernetes internal and external sources using KEDA
scalers. KEDA provides a wide variety of scalers to define
scaling behavior base on sources like CPU, Memory, Azure Event Hubs, Kafka, RabbitMQ, and more. We
use a ScaledObject to dynamically scale the instance count of our SpinApp to meet the demand.
Prerequisites
Please ensure the following tools are installed on your local machine:
- kubectl - the Kubernetes CLI
- Helm - the package manager for Kubernetes
- Docker - for running kind
- kind - a development Kubernetes distribution that runs on Docker
- Bombardier - cross-platform HTTP
benchmarking CLI
We use kind to run a Kubernetes cluster locally as part of this tutorial, but you can follow these
steps to configure KEDA autoscaling on your desired Kubernetes environment.
Setting Up Kubernetes Cluster
Run the following command to create a Kubernetes cluster that has the
containerd-shim-spin pre-requisites installed: If
you have a Kubernetes cluster already, or want to start with a more production ready SpinKube installation, follow the Helm installation guide instead, which include instructions for configuring the Runtime Class Manager for managing the lifecycle of the Spin containerd shim. The following kind cluster creation creates a three node cluster with containerd configuration to instruct containerd to use the Spin containerd shim for workloads scheduled with the spin runtime class. We are also exposing host port 8081 to make load testing easier in later steps.
cat <<EOF | kind create cluster --name wasm-cluster-scale --image ghcr.io/spinframework/containerd-shim-spin/kind:v0.25.0 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
containerdConfigPatches:
- |-
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin]
runtime_type = "io.containerd.spin.v2"
[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.spin.options]
SystemdCgroup = true
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 80
hostPort: 8081
protocol: TCP
- role: worker
- role: worker
EOF
Deploying Spin Operator and its dependencies
First, you have to install cert-manager to
automatically provision and manage TLS certificates (used by Spin Operator’s admission webhook
system). For detailed installation instructions see the cert-manager
documentation.
# Install cert-manager CRDs
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.crds.yaml
# Add and update Jetstack repository
helm repo add jetstack https://charts.jetstack.io
helm repo update
# Install the cert-manager Helm chart
helm install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.20.0
Next, run the following commands to install the Spin Runtime Class and Spin Operator Custom Resource Definitions (CRDs):
Note: In a production cluster you likely want to customize the Runtime Class with a nodeSelector
that matches nodes that have the shim installed. However, in the kind example, they’re installed on
every node.
# Install the RuntimeClass
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.runtime-class.yaml
# Install the CRDs
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.crds.yaml
Lastly, install Spin Operator using helm and the shim executor with the following commands:
# Install Spin Operator
helm install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
# Install the shim executor
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
Great, now you have Spin Operator up and running on your cluster. This means you’re set to create
and deploy SpinApps later on in the tutorial.
Install an Ingress Controller
Install an ingress controller in your cluster. This example uses Traefik as the ingress controller for local routing in Kind. We are requiring that it is run on the control-plane node where the hostPort is exposed.
helm repo add traefik https://helm.traefik.io/traefik
helm repo update
helm install traefik traefik/traefik \
--namespace traefik --create-namespace \
--set deployment.kind=DaemonSet \
--set service.type=ClusterIP \
--set ports.web.hostPort=80 \
--set tolerations[0].key=node-role.kubernetes.io/control-plane \
--set tolerations[0].effect=NoSchedule \
--set tolerations[0].operator=Exists \
--set nodeSelector."kubernetes\.io/hostname"=wasm-cluster-scale-control-plane
kubectl wait --namespace traefik --for=condition=ready pod --selector=app.kubernetes.io/name=traefik --timeout=180s
Set Up Ingress for the Spin App
Use the following command to set up ingress on your Kubernetes cluster. This ensures traffic can
reach your Spin App once we’ve created it in future steps:
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
annotations:
ingress.kubernetes.io/ssl-redirect: "false"
spec:
ingressClassName: traefik
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-spinapp
port:
number: 80
EOF
Setting Up KEDA
Use the following command to setup KEDA on your Kubernetes cluster using Helm. Different deployment
methods are described at Deploying KEDA on keda.sh:
# Add the Helm repository
helm repo add kedacore https://kedacore.github.io/charts
# Update your Helm repositories
helm repo update
# Install the keda Helm chart into the keda namespace
helm install keda kedacore/keda --namespace keda --create-namespace
Deploy Spin App and the KEDA ScaledObject
Next up we’re going to deploy the Spin App we will be scaling. You can find the source code of the
Spin App in the
apps/cpu-load-gen folder of
the Spin Operator repository.
We can take a look at the SpinApp and the KEDA ScaledObject definitions in our deployment files
below. As you can see, we have explicitly specified resource limits to 500m of cpu
(spec.resources.limits.cpu) and 500Mi of memory (spec.resources.limits.memory) per
SpinApp:
# https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/keda-app.yaml
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: keda-spinapp
spec:
image: ghcr.io/spinkube/spin-operator/cpu-load-gen:20240311-163328-g1121986
executor: containerd-shim-spin
enableAutoscaling: true
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 100m
memory: 400Mi
---
We will scale the instance count when we’ve reached a 50% utilization in cpu
(spec.triggers[cpu].metadata.value). We’ve also instructed KEDA to scale our SpinApp horizontally
within the range of 1 (spec.minReplicaCount) and 20 (spec.maxReplicaCount).:
# https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/keda-scaledobject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaling
spec:
scaleTargetRef:
name: keda-spinapp
minReplicaCount: 1
maxReplicaCount: 20
triggers:
- type: cpu
metricType: Utilization
metadata:
value: "50"
The Kubernetes documentation is the place to learn more about limits and
requests.
Consult the KEDA documentation to learn more about
ScaledObject and
KEDA’s built-in scalers.
Let’s deploy the SpinApp and the KEDA ScaledObject instance onto our cluster with the following
command:
# Deploy the SpinApp
kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/keda-app.yaml
spinapp.core.spinkube.dev/keda-spinapp created
# Deploy the ScaledObject
kubectl apply -f https://raw.githubusercontent.com/spinframework/spin-operator/main/config/samples/keda-scaledobject.yaml
scaledobject.keda.sh/cpu-scaling created
You can see your running Spin application by running the following command:
kubectl get spinapps
NAME READY REPLICAS EXECUTOR
keda-spinapp 1 containerd-shim-spin
You can also see your KEDA ScaledObject instance with the following command:
kubectl get scaledobject
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS READY ACTIVE AGE
cpu-scaling apps/v1.Deployment keda-spinapp 1 20 cpu True True 7m
Generate Load to Test Autoscale
Now let’s use Bombardier to generate traffic to test how well KEDA scales our SpinApp. The following
Bombardier command will attempt to establish 40 connections during a period of 3 minutes (or less).
If a request is not responded to within 5 seconds that request will timeout:
# Generate a bunch of load
bombardier -c 40 -t 5s -d 3m http://localhost:8081
To watch the load, we can run the following command to get the status of our deployment:
kubectl describe deploy keda-spinapp
...
---
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: keda-spinapp-76db5d7f9f (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 84s deployment-controller Scaled up replica set hpa-spinapp-76db5d7f9f to 2 from 1
Normal ScalingReplicaSet 69s deployment-controller Scaled up replica set hpa-spinapp-76db5d7f9f to 4 from 2
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set hpa-spinapp-76db5d7f9f to 8 from 4
Normal ScalingReplicaSet 39s deployment-controller Scaled up replica set hpa-spinapp-76db5d7f9f to 16 from 8
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set hpa-spinapp-76db5d7f9f to 20 from 16
3.11 - SpinKube at a glance
A high level overview of the SpinKube sub-projects.
spin-operator
Spin Operator is a Kubernetes
operator which empowers platform
engineers to deploy Spin applications as custom resources to
their Kubernetes clusters. Spin Operator provides an elegant solution for platform engineers looking
to improve efficiency without compromising on performance while maintaining workload portability.
Why Spin Operator?
By bringing the power of the Spin framework to Kubernetes clusters, Spin Operator provides
application developers and platform engineers with the best of both worlds. For developers, this
means easily building portable serverless functions that leverage the power and performance of Wasm
via the Spin developer tool. For platform engineers, this means using idiomatic Kubernetes
primitives (secrets, autoscaling, etc.) and tooling to manage these workloads at scale in a
production environment, improving their overall operational efficiency.
How Does Spin Operator Work?
Built with the kubebuilder framework, Spin
Operator is a Kubernetes operator. Kubernetes operators are used to extend Kubernetes automation to
new objects, defined as custom resources, without modifying the Kubernetes API. The Spin Operator is
composed of two main components:
- A controller that defines and manages Wasm workloads on k8s.
- The “SpinApps” Custom Resource Definition (CRD).

SpinApps CRDs can be composed manually or
generated automatically from an existing Spin application using the spin kube scaffold command. The former approach lends itself well to CI/CD systems,
whereas the latter is a better fit for local testing as part of a local developer workflow.
Once an application deployment begins, Spin Operator handles scheduling the workload on the
appropriate nodes (thanks to the Runtime Class Manager, previously known
as Kwasm) and managing the resource’s lifecycle. There is no need to fetch the
containerd-shim-spin binary or mutate node labels. This is all managed
via the Runtime Class Manager, which you will install as a dependency when setting up Spin Operator.
containerd-shim-spin
The containerd-shim-spin is a containerd
shim
implementation for Spin, which enables running Spin workloads
on Kubernetes via runwasi. This means that by installing this
shim onto Kubernetes nodes, we can add a runtime
class to Kubernetes and schedule
Spin workloads on those nodes. Your Spin apps can act just like container workloads!
The containerd-shim-spin is specifically designed to execute applications built with
Spin (a developer tool for building and running serverless Wasm
applications). The shim ensures that Wasm workloads can be managed effectively within a Kubernetes
environment, leveraging containerd’s capabilities.
In a Kubernetes cluster, specific nodes can be bootstrapped with Wasm runtimes and labeled
accordingly to facilitate the scheduling of Wasm workloads. RuntimeClasses in Kubernetes are used
to schedule Pods to specific nodes and target specific runtimes. By defining a RuntimeClass with
the appropriate NodeSelector and handler, Kubernetes can direct Wasm workloads to nodes equipped
with the necessary Wasm runtimes and ensure they are executed with the correct runtime handler.
Note: Runtime Class Manager automatically handles creation of the
appropriate RuntimeClass based on configuration supplied in Shim resources.
Overall, the Containerd Shim Spin represents a significant advancement in integrating Wasm workloads
into Kubernetes clusters, enhancing the versatility and capabilities of container orchestration.
runtime-class-manager
The Runtime Class Manager, also known as the Containerd Shim Lifecycle
Operator, is designed to automate and manage the
lifecycle of containerd shims in a Kubernetes environment. This includes tasks like installation,
update, removal, and configuration of shims, reducing manual errors and improving reliability in
managing WebAssembly (Wasm) workloads and other containerd extensions.
The Runtime Class Manager provides a robust and production-ready solution for installing, updating,
and removing shims, as well as managing node labels and runtime classes in a Kubernetes environment.
By automating these processes, the runtime-class-manager enhances reliability, reduces human error,
and simplifies the deployment and management of containerd shims in Kubernetes clusters.
spin-plugin-kube
The Kubernetes plugin for Spin is designed to
enhance Spin by enabling the execution of Wasm modules directly within a Kubernetes cluster.
Specifically a tool designed for Kubernetes integration with the Spin command-line interface. This
plugin works by integrating with containerd shims, allowing Kubernetes to manage and run Wasm
workloads in a way similar to traditional container workloads.
The Kubernetes plugin for Spin allows developers to use the Spin command-line interface for
deploying Spin applications; it provides a seamless workflow for building, pushing, deploying, and
managing Spin applications in a Kubernetes environment. It includes commands for scaffolding new
components as Kubernetes manifests, and deploying and retrieving information about Spin applications
running in Kubernetes. This plugin is an essential tool for developers looking to streamline their
Spin application deployment on Kubernetes platforms.
4 - API Reference
Technical references for APIs and other aspects of SpinKube’s machinery.
4.1 - SpinApp
Custom Resource Definition (CRD) reference for SpinApp
Resource Types:
SpinApp
SpinApp is the Schema for the spinapps API
| Name | Type | Description | Required |
|---|
| apiVersion | string | core.spinkube.dev/v1alpha1 | true |
| kind | string | SpinApp | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the `metadata` field. | true |
| spec | object | SpinAppSpec defines the desired state of SpinApp
| false |
| status | object | SpinAppStatus defines the observed state of SpinApp
| false |
SpinApp.spec
back to parent
SpinAppSpec defines the desired state of SpinApp
| Name | Type | Description | Required |
|---|
| executor | string | Executor controls how this app is executed in the cluster. Defaults to whatever executor is available on the cluster. If multiple
executors are available then the first executor in alphabetical order
will be chosen. If no executors are available then no default will be set.
| true |
| image | string | Image is the source for this app.
| true |
| checks | object | Checks defines health checks that should be used by Kubernetes to monitor the application.
| false |
| components | []string | Components of the app to execute. If this is not provided all components are executed.
| false |
| deploymentAnnotations | map[string]string | DeploymentAnnotations defines annotations to be applied to the underlying deployment.
| false |
| enableAutoscaling | boolean | EnableAutoscaling indicates whether the app is allowed to autoscale. If
true then the operator leaves the replica count of the underlying
deployment to be managed by an external autoscaler (HPA/KEDA). Replicas
cannot be defined if this is enabled. By default EnableAutoscaling is false.
Default: false
| false |
| imagePullSecrets | []object | ImagePullSecrets is a list of references to secrets in the same namespace to use for pulling the image.
| false |
| invocationLimits | map[string]string | InvocationLimits define limits to be applied per invocation of the app.
The keys are the names of the limits and the values are the limit values.
SpinKube executors may define their own limits.
| false |
| podAnnotations | map[string]string | PodAnnotations defines annotations to be applied to the underlying pods.
| false |
| podLabels | map[string]string | PodLabels defines labels to be applied to the underlying pods.
| false |
| replicas | integer | Number of replicas to run.
Format: int32
| false |
| resources | object | Resources defines the resource requirements for this app.
| false |
| runtimeConfig | object | RuntimeConfig defines configuration to be applied at runtime for this app.
| false |
| serviceAccountName | string | ServiceAccountName is the name of the Kubernetes service account to use for the pod.
If not specified, the default service account will be used.
| false |
| serviceAnnotations | map[string]string | ServiceAnnotations defines annotations to be applied to the underlying service.
| false |
| variables | []object | Variables provide Kubernetes Bindings to Spin App Variables.
| false |
| volumeMounts | []object | VolumeMounts defines how volumes are mounted in the underlying containers.
| false |
| volumes | []object | Volumes defines the volumes to be mounted in the underlying pods.
| false |
SpinApp.spec.checks
back to parent
Checks defines health checks that should be used by Kubernetes to monitor the application.
| Name | Type | Description | Required |
|---|
| liveness | object | Liveness defines the liveness probe for the application.
| false |
| readiness | object | Readiness defines the readiness probe for the application.
| false |
SpinApp.spec.checks.liveness
back to parent
Liveness defines the liveness probe for the application.
| Name | Type | Description | Required |
|---|
| failureThreshold | integer | Minimum consecutive failures for the probe to be considered failed after having succeeded.
Defaults to 3. Minimum value is 1.
Format: int32
Default: 3
| false |
| httpGet | object | HTTPGet describes a health check that should be performed using a GET request.
| false |
| initialDelaySeconds | integer | Number of seconds after the app has started before liveness probes are initiated.
Default 10s.
Format: int32
Default: 10
| false |
| periodSeconds | integer | How often (in seconds) to perform the probe.
Default to 10 seconds. Minimum value is 1.
Format: int32
Default: 10
| false |
| successThreshold | integer | Minimum consecutive successes for the probe to be considered successful after having failed.
Defaults to 1. Must be 1 for liveness and startup. Minimum value is 1.
Format: int32
Default: 1
| false |
| timeoutSeconds | integer | Number of seconds after which the probe times out.
Defaults to 1 second. Minimum value is 1.
Format: int32
Default: 1
| false |
SpinApp.spec.checks.liveness.httpGet
back to parent
HTTPGet describes a health check that should be performed using a GET request.
| Name | Type | Description | Required |
|---|
| path | string | Path is the path that should be used when calling the application for a
health check, e.g /healthz.
| true |
| httpHeaders | []object | HTTPHeaders are headers that should be included in the health check request.
| false |
back to parent
HTTPHealthProbeHeader is an abstraction around a http header key/value pair.
| Name | Type | Description | Required |
|---|
| name | string |
| true |
| value | string |
| true |
SpinApp.spec.checks.readiness
back to parent
Readiness defines the readiness probe for the application.
| Name | Type | Description | Required |
|---|
| failureThreshold | integer | Minimum consecutive failures for the probe to be considered failed after having succeeded.
Defaults to 3. Minimum value is 1.
Format: int32
Default: 3
| false |
| httpGet | object | HTTPGet describes a health check that should be performed using a GET request.
| false |
| initialDelaySeconds | integer | Number of seconds after the app has started before liveness probes are initiated.
Default 10s.
Format: int32
Default: 10
| false |
| periodSeconds | integer | How often (in seconds) to perform the probe.
Default to 10 seconds. Minimum value is 1.
Format: int32
Default: 10
| false |
| successThreshold | integer | Minimum consecutive successes for the probe to be considered successful after having failed.
Defaults to 1. Must be 1 for liveness and startup. Minimum value is 1.
Format: int32
Default: 1
| false |
| timeoutSeconds | integer | Number of seconds after which the probe times out.
Defaults to 1 second. Minimum value is 1.
Format: int32
Default: 1
| false |
SpinApp.spec.checks.readiness.httpGet
back to parent
HTTPGet describes a health check that should be performed using a GET request.
| Name | Type | Description | Required |
|---|
| path | string | Path is the path that should be used when calling the application for a
health check, e.g /healthz.
| true |
| httpHeaders | []object | HTTPHeaders are headers that should be included in the health check request.
| false |
back to parent
HTTPHealthProbeHeader is an abstraction around a http header key/value pair.
| Name | Type | Description | Required |
|---|
| name | string |
| true |
| value | string |
| true |
SpinApp.spec.imagePullSecrets[index]
back to parent
LocalObjectReference contains enough information to let you locate the
referenced object inside the same namespace.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.resources
back to parent
Resources defines the resource requirements for this app.
| Name | Type | Description | Required |
|---|
| limits | map[string]int or string | Limits describes the maximum amount of compute resources allowed.
| false |
| requests | map[string]int or string | Requests describes the minimum amount of compute resources required.
If Requests is omitted for a container, it defaults to Limits if that is explicitly specified,
otherwise to an implementation-defined value. Requests cannot exceed Limits.
| false |
SpinApp.spec.runtimeConfig
back to parent
RuntimeConfig defines configuration to be applied at runtime for this app.
| Name | Type | Description | Required |
|---|
| keyValueStores | []object |
| false |
| llmCompute | object |
| false |
| loadFromSecret | string | LoadFromSecret is the name of the secret to load runtime config from. The
secret should have a single key named "runtime-config.toml" that contains
the base64 encoded runtime config. If this is provided all other runtime
config is ignored.
| false |
| sqliteDatabases | []object | SqliteDatabases provides spin bindings to different SQLite database providers.
e.g on-disk or turso.
| false |
SpinApp.spec.runtimeConfig.keyValueStores[index]
back to parent
| Name | Type | Description | Required |
|---|
| name | string |
| true |
| type | string |
| true |
| options | []object |
| false |
SpinApp.spec.runtimeConfig.keyValueStores[index].options[index]
back to parent
| Name | Type | Description | Required |
|---|
| name | string | Name of the config option.
| true |
| value | string | Value is the static value to bind to the variable.
| false |
| valueFrom | object | ValueFrom is a reference to dynamically bind the variable to.
| false |
SpinApp.spec.runtimeConfig.keyValueStores[index].options[index].valueFrom
back to parent
ValueFrom is a reference to dynamically bind the variable to.
| Name | Type | Description | Required |
|---|
| configMapKeyRef | object | Selects a key of a ConfigMap.
| false |
| secretKeyRef | object | Selects a key of a secret in the apps namespace
| false |
SpinApp.spec.runtimeConfig.keyValueStores[index].options[index].valueFrom.configMapKeyRef
back to parent
Selects a key of a ConfigMap.
| Name | Type | Description | Required |
|---|
| key | string | The key to select.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the ConfigMap or its key must be defined
| false |
SpinApp.spec.runtimeConfig.keyValueStores[index].options[index].valueFrom.secretKeyRef
back to parent
Selects a key of a secret in the apps namespace
| Name | Type | Description | Required |
|---|
| key | string | The key of the secret to select from. Must be a valid secret key.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the Secret or its key must be defined
| false |
SpinApp.spec.runtimeConfig.llmCompute
back to parent
| Name | Type | Description | Required |
|---|
| type | string |
| true |
| options | []object |
| false |
SpinApp.spec.runtimeConfig.llmCompute.options[index]
back to parent
| Name | Type | Description | Required |
|---|
| name | string | Name of the config option.
| true |
| value | string | Value is the static value to bind to the variable.
| false |
| valueFrom | object | ValueFrom is a reference to dynamically bind the variable to.
| false |
SpinApp.spec.runtimeConfig.llmCompute.options[index].valueFrom
back to parent
ValueFrom is a reference to dynamically bind the variable to.
| Name | Type | Description | Required |
|---|
| configMapKeyRef | object | Selects a key of a ConfigMap.
| false |
| secretKeyRef | object | Selects a key of a secret in the apps namespace
| false |
SpinApp.spec.runtimeConfig.llmCompute.options[index].valueFrom.configMapKeyRef
back to parent
Selects a key of a ConfigMap.
| Name | Type | Description | Required |
|---|
| key | string | The key to select.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the ConfigMap or its key must be defined
| false |
SpinApp.spec.runtimeConfig.llmCompute.options[index].valueFrom.secretKeyRef
back to parent
Selects a key of a secret in the apps namespace
| Name | Type | Description | Required |
|---|
| key | string | The key of the secret to select from. Must be a valid secret key.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the Secret or its key must be defined
| false |
SpinApp.spec.runtimeConfig.sqliteDatabases[index]
back to parent
| Name | Type | Description | Required |
|---|
| name | string |
| true |
| type | string |
| true |
| options | []object |
| false |
SpinApp.spec.runtimeConfig.sqliteDatabases[index].options[index]
back to parent
| Name | Type | Description | Required |
|---|
| name | string | Name of the config option.
| true |
| value | string | Value is the static value to bind to the variable.
| false |
| valueFrom | object | ValueFrom is a reference to dynamically bind the variable to.
| false |
SpinApp.spec.runtimeConfig.sqliteDatabases[index].options[index].valueFrom
back to parent
ValueFrom is a reference to dynamically bind the variable to.
| Name | Type | Description | Required |
|---|
| configMapKeyRef | object | Selects a key of a ConfigMap.
| false |
| secretKeyRef | object | Selects a key of a secret in the apps namespace
| false |
SpinApp.spec.runtimeConfig.sqliteDatabases[index].options[index].valueFrom.configMapKeyRef
back to parent
Selects a key of a ConfigMap.
| Name | Type | Description | Required |
|---|
| key | string | The key to select.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the ConfigMap or its key must be defined
| false |
SpinApp.spec.runtimeConfig.sqliteDatabases[index].options[index].valueFrom.secretKeyRef
back to parent
Selects a key of a secret in the apps namespace
| Name | Type | Description | Required |
|---|
| key | string | The key of the secret to select from. Must be a valid secret key.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the Secret or its key must be defined
| false |
SpinApp.spec.variables[index]
back to parent
SpinVar defines a binding between a spin variable and a static or dynamic value.
| Name | Type | Description | Required |
|---|
| name | string | Name of the variable to bind.
| true |
| value | string | Value is the static value to bind to the variable.
| false |
| valueFrom | object | ValueFrom is a reference to dynamically bind the variable to.
| false |
SpinApp.spec.variables[index].valueFrom
back to parent
ValueFrom is a reference to dynamically bind the variable to.
| Name | Type | Description | Required |
|---|
| configMapKeyRef | object | Selects a key of a ConfigMap.
| false |
| fieldRef | object | Selects a field of the pod: supports metadata.name, metadata.namespace, `metadata.labels['']`, `metadata.annotations['']`,
spec.nodeName, spec.serviceAccountName, status.hostIP, status.podIP, status.podIPs.
| false |
| resourceFieldRef | object | Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, limits.ephemeral-storage, requests.cpu, requests.memory and requests.ephemeral-storage) are currently supported.
| false |
| secretKeyRef | object | Selects a key of a secret in the pod's namespace
| false |
SpinApp.spec.variables[index].valueFrom.configMapKeyRef
back to parent
Selects a key of a ConfigMap.
| Name | Type | Description | Required |
|---|
| key | string | The key to select.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the ConfigMap or its key must be defined
| false |
SpinApp.spec.variables[index].valueFrom.fieldRef
back to parent
Selects a field of the pod: supports metadata.name, metadata.namespace, metadata.labels['<KEY>'], metadata.annotations['<KEY>'],
spec.nodeName, spec.serviceAccountName, status.hostIP, status.podIP, status.podIPs.
| Name | Type | Description | Required |
|---|
| fieldPath | string | Path of the field to select in the specified API version.
| true |
| apiVersion | string | Version of the schema the FieldPath is written in terms of, defaults to "v1".
| false |
SpinApp.spec.variables[index].valueFrom.resourceFieldRef
back to parent
Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, limits.ephemeral-storage, requests.cpu, requests.memory and requests.ephemeral-storage) are currently supported.
| Name | Type | Description | Required |
|---|
| resource | string | Required: resource to select
| true |
| containerName | string | Container name: required for volumes, optional for env vars
| false |
| divisor | int or string | Specifies the output format of the exposed resources, defaults to "1"
| false |
SpinApp.spec.variables[index].valueFrom.secretKeyRef
back to parent
Selects a key of a secret in the pod’s namespace
| Name | Type | Description | Required |
|---|
| key | string | The key of the secret to select from. Must be a valid secret key.
| true |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | Specify whether the Secret or its key must be defined
| false |
SpinApp.spec.volumeMounts[index]
back to parent
VolumeMount describes a mounting of a Volume within a container.
| Name | Type | Description | Required |
|---|
| mountPath | string | Path within the container at which the volume should be mounted. Must
not contain ':'.
| true |
| name | string | This must match the Name of a Volume.
| true |
| mountPropagation | string | mountPropagation determines how mounts are propagated from the host
to container and the other way around.
When not set, MountPropagationNone is used.
This field is beta in 1.10.
When RecursiveReadOnly is set to IfPossible or to Enabled, MountPropagation must be None or unspecified
(which defaults to None).
| false |
| readOnly | boolean | Mounted read-only if true, read-write otherwise (false or unspecified).
Defaults to false.
| false |
| recursiveReadOnly | string | RecursiveReadOnly specifies whether read-only mounts should be handled
recursively. If ReadOnly is false, this field has no meaning and must be unspecified. If ReadOnly is true, and this field is set to Disabled, the mount is not made
recursively read-only. If this field is set to IfPossible, the mount is made
recursively read-only, if it is supported by the container runtime. If this
field is set to Enabled, the mount is made recursively read-only if it is
supported by the container runtime, otherwise the pod will not be started and
an error will be generated to indicate the reason. If this field is set to IfPossible or Enabled, MountPropagation must be set to
None (or be unspecified, which defaults to None). If this field is not specified, it is treated as an equivalent of Disabled.
| false |
| subPath | string | Path within the volume from which the container’s volume should be mounted.
Defaults to "" (volume’s root).
| false |
| subPathExpr | string | Expanded path within the volume from which the container’s volume should be mounted.
Behaves similarly to SubPath but environment variable references $(VAR_NAME) are expanded using the container’s environment.
Defaults to "" (volume’s root).
SubPathExpr and SubPath are mutually exclusive.
| false |
SpinApp.spec.volumes[index]
back to parent
Volume represents a named volume in a pod that may be accessed by any container in the pod.
| Name | Type | Description | Required |
|---|
| name | string | name of the volume.
Must be a DNS_LABEL and unique within the pod.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
| true |
| awsElasticBlockStore | object | awsElasticBlockStore represents an AWS Disk resource that is attached to a
kubelet's host machine and then exposed to the pod.
Deprecated: AWSElasticBlockStore is deprecated. All operations for the in-tree
awsElasticBlockStore type are redirected to the ebs.csi.aws.com CSI driver.
More info: https://kubernetes.io/docs/concepts/storage/volumes#awselasticblockstore
| false |
| azureDisk | object | azureDisk represents an Azure Data Disk mount on the host and bind mount to the pod.
Deprecated: AzureDisk is deprecated. All operations for the in-tree azureDisk type
are redirected to the disk.csi.azure.com CSI driver.
| false |
| azureFile | object | azureFile represents an Azure File Service mount on the host and bind mount to the pod.
Deprecated: AzureFile is deprecated. All operations for the in-tree azureFile type
are redirected to the file.csi.azure.com CSI driver.
| false |
| cephfs | object | cephFS represents a Ceph FS mount on the host that shares a pod's lifetime.
Deprecated: CephFS is deprecated and the in-tree cephfs type is no longer supported.
| false |
| cinder | object | cinder represents a cinder volume attached and mounted on kubelets host machine.
Deprecated: Cinder is deprecated. All operations for the in-tree cinder type
are redirected to the cinder.csi.openstack.org CSI driver.
More info: https://examples.k8s.io/mysql-cinder-pd/README.md
| false |
| configMap | object | configMap represents a configMap that should populate this volume
| false |
| csi | object | csi (Container Storage Interface) represents ephemeral storage that is handled by certain external CSI drivers.
| false |
| downwardAPI | object | downwardAPI represents downward API about the pod that should populate this volume
| false |
| emptyDir | object | emptyDir represents a temporary directory that shares a pod's lifetime.
More info: https://kubernetes.io/docs/concepts/storage/volumes#emptydir
| false |
| ephemeral | object | ephemeral represents a volume that is handled by a cluster storage driver.
The volume's lifecycle is tied to the pod that defines it - it will be created before the pod starts,
and deleted when the pod is removed. Use this if:
a) the volume is only needed while the pod runs,
b) features of normal volumes like restoring from snapshot or capacity
tracking are needed,
c) the storage driver is specified through a storage class, and
d) the storage driver supports dynamic volume provisioning through
a PersistentVolumeClaim (see EphemeralVolumeSource for more
information on the connection between this volume type
and PersistentVolumeClaim). Use PersistentVolumeClaim or one of the vendor-specific
APIs for volumes that persist for longer than the lifecycle
of an individual pod. Use CSI for light-weight local ephemeral volumes if the CSI driver is meant to
be used that way - see the documentation of the driver for
more information. A pod can use both types of ephemeral volumes and
persistent volumes at the same time.
| false |
| fc | object | fc represents a Fibre Channel resource that is attached to a kubelet’s host machine and then exposed to the pod.
| false |
| flexVolume | object | flexVolume represents a generic volume resource that is
provisioned/attached using an exec based plugin.
Deprecated: FlexVolume is deprecated. Consider using a CSIDriver instead.
| false |
| flocker | object | flocker represents a Flocker volume attached to a kubelet’s host machine. This depends on the Flocker control service being running.
Deprecated: Flocker is deprecated and the in-tree flocker type is no longer supported.
| false |
| gcePersistentDisk | object | gcePersistentDisk represents a GCE Disk resource that is attached to a
kubelet’s host machine and then exposed to the pod.
Deprecated: GCEPersistentDisk is deprecated. All operations for the in-tree
gcePersistentDisk type are redirected to the pd.csi.storage.gke.io CSI driver.
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
| false |
| gitRepo | object | gitRepo represents a git repository at a particular revision.
Deprecated: GitRepo is deprecated. To provision a container with a git repo, mount an
EmptyDir into an InitContainer that clones the repo using git, then mount the EmptyDir
into the Pod’s container.
| false |
| glusterfs | object | glusterfs represents a Glusterfs mount on the host that shares a pod’s lifetime.
Deprecated: Glusterfs is deprecated and the in-tree glusterfs type is no longer supported.
More info: https://examples.k8s.io/volumes/glusterfs/README.md
| false |
| hostPath | object | hostPath represents a pre-existing file or directory on the host
machine that is directly exposed to the container. This is generally
used for system agents or other privileged things that are allowed
to see the host machine. Most containers will NOT need this.
More info: https://kubernetes.io/docs/concepts/storage/volumes#hostpath
| false |
| image | object | image represents an OCI object (a container image or artifact) pulled and mounted on the kubelet’s host machine.
The volume is resolved at pod startup depending on which PullPolicy value is provided:- Always: the kubelet always attempts to pull the reference. Container creation will fail If the pull fails.
- Never: the kubelet never pulls the reference and only uses a local image or artifact. Container creation will fail if the reference isn’t present.
- IfNotPresent: the kubelet pulls if the reference isn’t already present on disk. Container creation will fail if the reference isn’t present and the pull fails.
The volume gets re-resolved if the pod gets deleted and recreated, which means that new remote content will become available on pod recreation.
A failure to resolve or pull the image during pod startup will block containers from starting and may add significant latency. Failures will be retried using normal volume backoff and will be reported on the pod reason and message.
The types of objects that may be mounted by this volume are defined by the container runtime implementation on a host machine and at minimum must include all valid types supported by the container image field.
The OCI object gets mounted in a single directory (spec.containers[].volumeMounts.mountPath) by merging the manifest layers in the same way as for container images.
The volume will be mounted read-only (ro) and non-executable files (noexec).
Sub path mounts for containers are not supported (spec.containers[].volumeMounts.subpath) before 1.33.
The field spec.securityContext.fsGroupChangePolicy has no effect on this volume type.
| false |
| iscsi | object | iscsi represents an ISCSI Disk resource that is attached to a
kubelet’s host machine and then exposed to the pod.
More info: https://examples.k8s.io/volumes/iscsi/README.md
| false |
| nfs | object | nfs represents an NFS mount on the host that shares a pod’s lifetime
More info: https://kubernetes.io/docs/concepts/storage/volumes#nfs
| false |
| persistentVolumeClaim | object | persistentVolumeClaimVolumeSource represents a reference to a
PersistentVolumeClaim in the same namespace.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#persistentvolumeclaims
| false |
| photonPersistentDisk | object | photonPersistentDisk represents a PhotonController persistent disk attached and mounted on kubelets host machine.
Deprecated: PhotonPersistentDisk is deprecated and the in-tree photonPersistentDisk type is no longer supported.
| false |
| portworxVolume | object | portworxVolume represents a portworx volume attached and mounted on kubelets host machine.
Deprecated: PortworxVolume is deprecated. All operations for the in-tree portworxVolume type
are redirected to the pxd.portworx.com CSI driver when the CSIMigrationPortworx feature-gate
is on.
| false |
| projected | object | projected items for all in one resources secrets, configmaps, and downward API
| false |
| quobyte | object | quobyte represents a Quobyte mount on the host that shares a pod’s lifetime.
Deprecated: Quobyte is deprecated and the in-tree quobyte type is no longer supported.
| false |
| rbd | object | rbd represents a Rados Block Device mount on the host that shares a pod’s lifetime.
Deprecated: RBD is deprecated and the in-tree rbd type is no longer supported.
More info: https://examples.k8s.io/volumes/rbd/README.md
| false |
| scaleIO | object | scaleIO represents a ScaleIO persistent volume attached and mounted on Kubernetes nodes.
Deprecated: ScaleIO is deprecated and the in-tree scaleIO type is no longer supported.
| false |
| secret | object | secret represents a secret that should populate this volume.
More info: https://kubernetes.io/docs/concepts/storage/volumes#secret
| false |
| storageos | object | storageOS represents a StorageOS volume attached and mounted on Kubernetes nodes.
Deprecated: StorageOS is deprecated and the in-tree storageos type is no longer supported.
| false |
| vsphereVolume | object | vsphereVolume represents a vSphere volume attached and mounted on kubelets host machine.
Deprecated: VsphereVolume is deprecated. All operations for the in-tree vsphereVolume type
are redirected to the csi.vsphere.vmware.com CSI driver.
| false |
SpinApp.spec.volumes[index].awsElasticBlockStore
back to parent
awsElasticBlockStore represents an AWS Disk resource that is attached to a
kubelet’s host machine and then exposed to the pod.
Deprecated: AWSElasticBlockStore is deprecated. All operations for the in-tree
awsElasticBlockStore type are redirected to the ebs.csi.aws.com CSI driver.
More info: https://kubernetes.io/docs/concepts/storage/volumes#awselasticblockstore
| Name | Type | Description | Required |
|---|
| volumeID | string | volumeID is unique ID of the persistent disk resource in AWS (Amazon EBS volume).
More info: https://kubernetes.io/docs/concepts/storage/volumes#awselasticblockstore
| true |
| fsType | string | fsType is the filesystem type of the volume that you want to mount.
Tip: Ensure that the filesystem type is supported by the host operating system.
Examples: "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
More info: https://kubernetes.io/docs/concepts/storage/volumes#awselasticblockstore
| false |
| partition | integer | partition is the partition in the volume that you want to mount.
If omitted, the default is to mount by volume name.
Examples: For volume /dev/sda1, you specify the partition as "1".
Similarly, the volume partition for /dev/sda is "0" (or you can leave the property empty).
Format: int32
| false |
| readOnly | boolean | readOnly value true will force the readOnly setting in VolumeMounts.
More info: https://kubernetes.io/docs/concepts/storage/volumes#awselasticblockstore
| false |
SpinApp.spec.volumes[index].azureDisk
back to parent
azureDisk represents an Azure Data Disk mount on the host and bind mount to the pod.
Deprecated: AzureDisk is deprecated. All operations for the in-tree azureDisk type
are redirected to the disk.csi.azure.com CSI driver.
| Name | Type | Description | Required |
|---|
| diskName | string | diskName is the Name of the data disk in the blob storage
| true |
| diskURI | string | diskURI is the URI of data disk in the blob storage
| true |
| cachingMode | string | cachingMode is the Host Caching mode: None, Read Only, Read Write.
| false |
| fsType | string | fsType is Filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
Default: ext4
| false |
| kind | string | kind expected values are Shared: multiple blob disks per storage account Dedicated: single blob disk per storage account Managed: azure managed data disk (only in managed availability set). defaults to shared
| false |
| readOnly | boolean | readOnly Defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
Default: false
| false |
SpinApp.spec.volumes[index].azureFile
back to parent
azureFile represents an Azure File Service mount on the host and bind mount to the pod.
Deprecated: AzureFile is deprecated. All operations for the in-tree azureFile type
are redirected to the file.csi.azure.com CSI driver.
| Name | Type | Description | Required |
|---|
| secretName | string | secretName is the name of secret that contains Azure Storage Account Name and Key
| true |
| shareName | string | shareName is the azure share Name
| true |
| readOnly | boolean | readOnly defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
SpinApp.spec.volumes[index].cephfs
back to parent
cephFS represents a Ceph FS mount on the host that shares a pod’s lifetime.
Deprecated: CephFS is deprecated and the in-tree cephfs type is no longer supported.
| Name | Type | Description | Required |
|---|
| monitors | []string | monitors is Required: Monitors is a collection of Ceph monitors
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| true |
| path | string | path is Optional: Used as the mounted root, rather than the full Ceph tree, default is /
| false |
| readOnly | boolean | readOnly is Optional: Defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| false |
| secretFile | string | secretFile is Optional: SecretFile is the path to key ring for User, default is /etc/ceph/user.secret
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| false |
| secretRef | object | secretRef is Optional: SecretRef is reference to the authentication secret for User, default is empty.
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| false |
| user | string | user is optional: User is the rados user name, default is admin
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| false |
SpinApp.spec.volumes[index].cephfs.secretRef
back to parent
secretRef is Optional: SecretRef is reference to the authentication secret for User, default is empty.
More info: https://examples.k8s.io/volumes/cephfs/README.md#how-to-use-it
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].cinder
back to parent
cinder represents a cinder volume attached and mounted on kubelets host machine.
Deprecated: Cinder is deprecated. All operations for the in-tree cinder type
are redirected to the cinder.csi.openstack.org CSI driver.
More info: https://examples.k8s.io/mysql-cinder-pd/README.md
| Name | Type | Description | Required |
|---|
| volumeID | string | volumeID used to identify the volume in cinder.
More info: https://examples.k8s.io/mysql-cinder-pd/README.md
| true |
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Examples: "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
More info: https://examples.k8s.io/mysql-cinder-pd/README.md
| false |
| readOnly | boolean | readOnly defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
More info: https://examples.k8s.io/mysql-cinder-pd/README.md
| false |
| secretRef | object | secretRef is optional: points to a secret object containing parameters used to connect
to OpenStack.
| false |
SpinApp.spec.volumes[index].cinder.secretRef
back to parent
secretRef is optional: points to a secret object containing parameters used to connect
to OpenStack.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].configMap
back to parent
configMap represents a configMap that should populate this volume
| Name | Type | Description | Required |
|---|
| defaultMode | integer | defaultMode is optional: mode bits used to set permissions on created files by default.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
Defaults to 0644.
Directories within the path are not affected by this setting.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| items | []object | items if unspecified, each key-value pair in the Data field of the referenced
ConfigMap will be projected into the volume as a file whose name is the
key and content is the value. If specified, the listed keys will be
projected into the specified paths, and unlisted keys will not be
present. If a key is specified which is not present in the ConfigMap,
the volume setup will error unless it is marked optional. Paths must be
relative and may not contain the '..' path or start with '..'.
| false |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | optional specify whether the ConfigMap or its keys must be defined
| false |
SpinApp.spec.volumes[index].configMap.items[index]
back to parent
Maps a string key to a path within a volume.
| Name | Type | Description | Required |
|---|
| key | string | key is the key to project.
| true |
| path | string | path is the relative path of the file to map the key to.
May not be an absolute path.
May not contain the path element '..'.
May not start with the string '..'.
| true |
| mode | integer | mode is Optional: mode bits used to set permissions on this file.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
SpinApp.spec.volumes[index].csi
back to parent
csi (Container Storage Interface) represents ephemeral storage that is handled by certain external CSI drivers.
| Name | Type | Description | Required |
|---|
| driver | string | driver is the name of the CSI driver that handles this volume.
Consult with your admin for the correct name as registered in the cluster.
| true |
| fsType | string | fsType to mount. Ex. "ext4", "xfs", "ntfs".
If not provided, the empty value is passed to the associated CSI driver
which will determine the default filesystem to apply.
| false |
| nodePublishSecretRef | object | nodePublishSecretRef is a reference to the secret object containing
sensitive information to pass to the CSI driver to complete the CSI
NodePublishVolume and NodeUnpublishVolume calls.
This field is optional, and may be empty if no secret is required. If the
secret object contains more than one secret, all secret references are passed.
| false |
| readOnly | boolean | readOnly specifies a read-only configuration for the volume.
Defaults to false (read/write).
| false |
| volumeAttributes | map[string]string | volumeAttributes stores driver-specific properties that are passed to the CSI
driver. Consult your driver's documentation for supported values.
| false |
SpinApp.spec.volumes[index].csi.nodePublishSecretRef
back to parent
nodePublishSecretRef is a reference to the secret object containing
sensitive information to pass to the CSI driver to complete the CSI
NodePublishVolume and NodeUnpublishVolume calls.
This field is optional, and may be empty if no secret is required. If the
secret object contains more than one secret, all secret references are passed.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].downwardAPI
back to parent
downwardAPI represents downward API about the pod that should populate this volume
| Name | Type | Description | Required |
|---|
| defaultMode | integer | Optional: mode bits to use on created files by default. Must be a
Optional: mode bits used to set permissions on created files by default.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
Defaults to 0644.
Directories within the path are not affected by this setting.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| items | []object | Items is a list of downward API volume file
| false |
SpinApp.spec.volumes[index].downwardAPI.items[index]
back to parent
DownwardAPIVolumeFile represents information to create the file containing the pod field
| Name | Type | Description | Required |
|---|
| path | string | Required: Path is the relative path name of the file to be created. Must not be absolute or contain the '..' path. Must be utf-8 encoded. The first item of the relative path must not start with '..'
| true |
| fieldRef | object | Required: Selects a field of the pod: only annotations, labels, name, namespace and uid are supported.
| false |
| mode | integer | Optional: mode bits used to set permissions on this file, must be an octal value
between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| resourceFieldRef | object | Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, requests.cpu and requests.memory) are currently supported.
| false |
SpinApp.spec.volumes[index].downwardAPI.items[index].fieldRef
back to parent
Required: Selects a field of the pod: only annotations, labels, name, namespace and uid are supported.
| Name | Type | Description | Required |
|---|
| fieldPath | string | Path of the field to select in the specified API version.
| true |
| apiVersion | string | Version of the schema the FieldPath is written in terms of, defaults to "v1".
| false |
SpinApp.spec.volumes[index].downwardAPI.items[index].resourceFieldRef
back to parent
Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, requests.cpu and requests.memory) are currently supported.
| Name | Type | Description | Required |
|---|
| resource | string | Required: resource to select
| true |
| containerName | string | Container name: required for volumes, optional for env vars
| false |
| divisor | int or string | Specifies the output format of the exposed resources, defaults to "1"
| false |
SpinApp.spec.volumes[index].emptyDir
back to parent
emptyDir represents a temporary directory that shares a pod’s lifetime.
More info: https://kubernetes.io/docs/concepts/storage/volumes#emptydir
| Name | Type | Description | Required |
|---|
| medium | string | medium represents what type of storage medium should back this directory.
The default is "" which means to use the node's default medium.
Must be an empty string (default) or Memory.
More info: https://kubernetes.io/docs/concepts/storage/volumes#emptydir
| false |
| sizeLimit | int or string | sizeLimit is the total amount of local storage required for this EmptyDir volume.
The size limit is also applicable for memory medium.
The maximum usage on memory medium EmptyDir would be the minimum value between
the SizeLimit specified here and the sum of memory limits of all containers in a pod.
The default is nil which means that the limit is undefined.
More info: https://kubernetes.io/docs/concepts/storage/volumes#emptydir
| false |
SpinApp.spec.volumes[index].ephemeral
back to parent
ephemeral represents a volume that is handled by a cluster storage driver.
The volume’s lifecycle is tied to the pod that defines it - it will be created before the pod starts,
and deleted when the pod is removed.
Use this if:
a) the volume is only needed while the pod runs,
b) features of normal volumes like restoring from snapshot or capacity
tracking are needed,
c) the storage driver is specified through a storage class, and
d) the storage driver supports dynamic volume provisioning through
a PersistentVolumeClaim (see EphemeralVolumeSource for more
information on the connection between this volume type
and PersistentVolumeClaim).
Use PersistentVolumeClaim or one of the vendor-specific
APIs for volumes that persist for longer than the lifecycle
of an individual pod.
Use CSI for light-weight local ephemeral volumes if the CSI driver is meant to
be used that way - see the documentation of the driver for
more information.
A pod can use both types of ephemeral volumes and
persistent volumes at the same time.
| Name | Type | Description | Required |
|---|
| volumeClaimTemplate | object | Will be used to create a stand-alone PVC to provision the volume.
The pod in which this EphemeralVolumeSource is embedded will be the
owner of the PVC, i.e. the PVC will be deleted together with the
pod. The name of the PVC will be `-` where
`` is the name from the `PodSpec.Volumes` array
entry. Pod validation will reject the pod if the concatenated name
is not valid for a PVC (for example, too long). An existing PVC with that name that is not owned by the pod
will not be used for the pod to avoid using an unrelated
volume by mistake. Starting the pod is then blocked until
the unrelated PVC is removed. If such a pre-created PVC is
meant to be used by the pod, the PVC has to updated with an
owner reference to the pod once the pod exists. Normally
this should not be necessary, but it may be useful when
manually reconstructing a broken cluster. This field is read-only and no changes will be made by Kubernetes
to the PVC after it has been created. Required, must not be nil.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate
back to parent
Will be used to create a stand-alone PVC to provision the volume.
The pod in which this EphemeralVolumeSource is embedded will be the
owner of the PVC, i.e. the PVC will be deleted together with the
pod. The name of the PVC will be <pod name>-<volume name> where
<volume name> is the name from the PodSpec.Volumes array
entry. Pod validation will reject the pod if the concatenated name
is not valid for a PVC (for example, too long).
An existing PVC with that name that is not owned by the pod
will not be used for the pod to avoid using an unrelated
volume by mistake. Starting the pod is then blocked until
the unrelated PVC is removed. If such a pre-created PVC is
meant to be used by the pod, the PVC has to updated with an
owner reference to the pod once the pod exists. Normally
this should not be necessary, but it may be useful when
manually reconstructing a broken cluster.
This field is read-only and no changes will be made by Kubernetes
to the PVC after it has been created.
Required, must not be nil.
| Name | Type | Description | Required |
|---|
| spec | object | The specification for the PersistentVolumeClaim. The entire content is
copied unchanged into the PVC that gets created from this
template. The same fields as in a PersistentVolumeClaim
are also valid here.
| true |
| metadata | object | May contain labels and annotations that will be copied into the PVC
when creating it. No other fields are allowed and will be rejected during
validation.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec
back to parent
The specification for the PersistentVolumeClaim. The entire content is
copied unchanged into the PVC that gets created from this
template. The same fields as in a PersistentVolumeClaim
are also valid here.
| Name | Type | Description | Required |
|---|
| accessModes | []string | accessModes contains the desired access modes the volume should have.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#access-modes-1
| false |
| dataSource | object | dataSource field can be used to specify either:
* An existing VolumeSnapshot object (snapshot.storage.k8s.io/VolumeSnapshot)
* An existing PVC (PersistentVolumeClaim)
If the provisioner or an external controller can support the specified data source,
it will create a new volume based on the contents of the specified data source.
When the AnyVolumeDataSource feature gate is enabled, dataSource contents will be copied to dataSourceRef,
and dataSourceRef contents will be copied to dataSource when dataSourceRef.namespace is not specified.
If the namespace is specified, then dataSourceRef will not be copied to dataSource.
| false |
| dataSourceRef | object | dataSourceRef specifies the object from which to populate the volume with data, if a non-empty
volume is desired. This may be any object from a non-empty API group (non
core object) or a PersistentVolumeClaim object.
When this field is specified, volume binding will only succeed if the type of
the specified object matches some installed volume populator or dynamic
provisioner.
This field will replace the functionality of the dataSource field and as such
if both fields are non-empty, they must have the same value. For backwards
compatibility, when namespace isn't specified in dataSourceRef,
both fields (dataSource and dataSourceRef) will be set to the same
value automatically if one of them is empty and the other is non-empty.
When namespace is specified in dataSourceRef,
dataSource isn't set to the same value and must be empty.
There are three important differences between dataSource and dataSourceRef:
* While dataSource only allows two specific types of objects, dataSourceRef
allows any non-core object, as well as PersistentVolumeClaim objects.
* While dataSource ignores disallowed values (dropping them), dataSourceRef
preserves all values, and generates an error if a disallowed value is
specified.
* While dataSource only allows local objects, dataSourceRef allows objects
in any namespaces.
(Beta) Using this field requires the AnyVolumeDataSource feature gate to be enabled.
(Alpha) Using the namespace field of dataSourceRef requires the CrossNamespaceVolumeDataSource feature gate to be enabled.
| false |
| resources | object | resources represents the minimum resources the volume should have.
If RecoverVolumeExpansionFailure feature is enabled users are allowed to specify resource requirements
that are lower than previous value but must still be higher than capacity recorded in the
status field of the claim.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#resources
| false |
| selector | object | selector is a label query over volumes to consider for binding.
| false |
| storageClassName | string | storageClassName is the name of the StorageClass required by the claim.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#class-1
| false |
| volumeAttributesClassName | string | volumeAttributesClassName may be used to set the VolumeAttributesClass used by this claim.
If specified, the CSI driver will create or update the volume with the attributes defined
in the corresponding VolumeAttributesClass. This has a different purpose than storageClassName,
it can be changed after the claim is created. An empty string value means that no VolumeAttributesClass
will be applied to the claim but it's not allowed to reset this field to empty string once it is set.
If unspecified and the PersistentVolumeClaim is unbound, the default VolumeAttributesClass
will be set by the persistentvolume controller if it exists.
If the resource referred to by volumeAttributesClass does not exist, this PersistentVolumeClaim will be
set to a Pending state, as reflected by the modifyVolumeStatus field, until such as a resource
exists.
More info: https://kubernetes.io/docs/concepts/storage/volume-attributes-classes/
(Beta) Using this field requires the VolumeAttributesClass feature gate to be enabled (off by default).
| false |
| volumeMode | string | volumeMode defines what type of volume is required by the claim.
Value of Filesystem is implied when not included in claim spec.
| false |
| volumeName | string | volumeName is the binding reference to the PersistentVolume backing this claim.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec.dataSource
back to parent
dataSource field can be used to specify either:
- An existing VolumeSnapshot object (snapshot.storage.k8s.io/VolumeSnapshot)
- An existing PVC (PersistentVolumeClaim)
If the provisioner or an external controller can support the specified data source,
it will create a new volume based on the contents of the specified data source.
When the AnyVolumeDataSource feature gate is enabled, dataSource contents will be copied to dataSourceRef,
and dataSourceRef contents will be copied to dataSource when dataSourceRef.namespace is not specified.
If the namespace is specified, then dataSourceRef will not be copied to dataSource.
| Name | Type | Description | Required |
|---|
| kind | string | Kind is the type of resource being referenced
| true |
| name | string | Name is the name of resource being referenced
| true |
| apiGroup | string | APIGroup is the group for the resource being referenced.
If APIGroup is not specified, the specified Kind must be in the core API group.
For any other third-party types, APIGroup is required.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec.dataSourceRef
back to parent
dataSourceRef specifies the object from which to populate the volume with data, if a non-empty
volume is desired. This may be any object from a non-empty API group (non
core object) or a PersistentVolumeClaim object.
When this field is specified, volume binding will only succeed if the type of
the specified object matches some installed volume populator or dynamic
provisioner.
This field will replace the functionality of the dataSource field and as such
if both fields are non-empty, they must have the same value. For backwards
compatibility, when namespace isn’t specified in dataSourceRef,
both fields (dataSource and dataSourceRef) will be set to the same
value automatically if one of them is empty and the other is non-empty.
When namespace is specified in dataSourceRef,
dataSource isn’t set to the same value and must be empty.
There are three important differences between dataSource and dataSourceRef:
- While dataSource only allows two specific types of objects, dataSourceRef
allows any non-core object, as well as PersistentVolumeClaim objects.
- While dataSource ignores disallowed values (dropping them), dataSourceRef
preserves all values, and generates an error if a disallowed value is
specified.
- While dataSource only allows local objects, dataSourceRef allows objects
in any namespaces.
(Beta) Using this field requires the AnyVolumeDataSource feature gate to be enabled.
(Alpha) Using the namespace field of dataSourceRef requires the CrossNamespaceVolumeDataSource feature gate to be enabled.
| Name | Type | Description | Required |
|---|
| kind | string | Kind is the type of resource being referenced
| true |
| name | string | Name is the name of resource being referenced
| true |
| apiGroup | string | APIGroup is the group for the resource being referenced.
If APIGroup is not specified, the specified Kind must be in the core API group.
For any other third-party types, APIGroup is required.
| false |
| namespace | string | Namespace is the namespace of resource being referenced
Note that when a namespace is specified, a gateway.networking.k8s.io/ReferenceGrant object is required in the referent namespace to allow that namespace's owner to accept the reference. See the ReferenceGrant documentation for details.
(Alpha) This field requires the CrossNamespaceVolumeDataSource feature gate to be enabled.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec.resources
back to parent
resources represents the minimum resources the volume should have.
If RecoverVolumeExpansionFailure feature is enabled users are allowed to specify resource requirements
that are lower than previous value but must still be higher than capacity recorded in the
status field of the claim.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#resources
| Name | Type | Description | Required |
|---|
| limits | map[string]int or string | Limits describes the maximum amount of compute resources allowed.
More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
| false |
| requests | map[string]int or string | Requests describes the minimum amount of compute resources required.
If Requests is omitted for a container, it defaults to Limits if that is explicitly specified,
otherwise to an implementation-defined value. Requests cannot exceed Limits.
More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec.selector
back to parent
selector is a label query over volumes to consider for binding.
| Name | Type | Description | Required |
|---|
| matchExpressions | []object | matchExpressions is a list of label selector requirements. The requirements are ANDed.
| false |
| matchLabels | map[string]string | matchLabels is a map of {key,value} pairs. A single {key,value} in the matchLabels
map is equivalent to an element of matchExpressions, whose key field is "key", the
operator is "In", and the values array contains only "value". The requirements are ANDed.
| false |
SpinApp.spec.volumes[index].ephemeral.volumeClaimTemplate.spec.selector.matchExpressions[index]
back to parent
A label selector requirement is a selector that contains values, a key, and an operator that
relates the key and values.
| Name | Type | Description | Required |
|---|
| key | string | key is the label key that the selector applies to.
| true |
| operator | string | operator represents a key's relationship to a set of values.
Valid operators are In, NotIn, Exists and DoesNotExist.
| true |
| values | []string | values is an array of string values. If the operator is In or NotIn,
the values array must be non-empty. If the operator is Exists or DoesNotExist,
the values array must be empty. This array is replaced during a strategic
merge patch.
| false |
SpinApp.spec.volumes[index].fc
back to parent
fc represents a Fibre Channel resource that is attached to a kubelet’s host machine and then exposed to the pod.
| Name | Type | Description | Required |
|---|
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
| false |
| lun | integer | lun is Optional: FC target lun number
Format: int32
| false |
| readOnly | boolean | readOnly is Optional: Defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
| targetWWNs | []string | targetWWNs is Optional: FC target worldwide names (WWNs)
| false |
| wwids | []string | wwids Optional: FC volume world wide identifiers (wwids)
Either wwids or combination of targetWWNs and lun must be set, but not both simultaneously.
| false |
SpinApp.spec.volumes[index].flexVolume
back to parent
flexVolume represents a generic volume resource that is
provisioned/attached using an exec based plugin.
Deprecated: FlexVolume is deprecated. Consider using a CSIDriver instead.
| Name | Type | Description | Required |
|---|
| driver | string | driver is the name of the driver to use for this volume.
| true |
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". The default filesystem depends on FlexVolume script.
| false |
| options | map[string]string | options is Optional: this field holds extra command options if any.
| false |
| readOnly | boolean | readOnly is Optional: defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
| secretRef | object | secretRef is Optional: secretRef is reference to the secret object containing
sensitive information to pass to the plugin scripts. This may be
empty if no secret object is specified. If the secret object
contains more than one secret, all secrets are passed to the plugin
scripts.
| false |
SpinApp.spec.volumes[index].flexVolume.secretRef
back to parent
secretRef is Optional: secretRef is reference to the secret object containing
sensitive information to pass to the plugin scripts. This may be
empty if no secret object is specified. If the secret object
contains more than one secret, all secrets are passed to the plugin
scripts.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].flocker
back to parent
flocker represents a Flocker volume attached to a kubelet’s host machine. This depends on the Flocker control service being running.
Deprecated: Flocker is deprecated and the in-tree flocker type is no longer supported.
| Name | Type | Description | Required |
|---|
| datasetName | string | datasetName is Name of the dataset stored as metadata -> name on the dataset for Flocker
should be considered as deprecated
| false |
| datasetUUID | string | datasetUUID is the UUID of the dataset. This is unique identifier of a Flocker dataset
| false |
SpinApp.spec.volumes[index].gcePersistentDisk
back to parent
gcePersistentDisk represents a GCE Disk resource that is attached to a
kubelet’s host machine and then exposed to the pod.
Deprecated: GCEPersistentDisk is deprecated. All operations for the in-tree
gcePersistentDisk type are redirected to the pd.csi.storage.gke.io CSI driver.
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
| Name | Type | Description | Required |
|---|
| pdName | string | pdName is unique name of the PD resource in GCE. Used to identify the disk in GCE.
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
| true |
| fsType | string | fsType is filesystem type of the volume that you want to mount.
Tip: Ensure that the filesystem type is supported by the host operating system.
Examples: "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
| false |
| partition | integer | partition is the partition in the volume that you want to mount.
If omitted, the default is to mount by volume name.
Examples: For volume /dev/sda1, you specify the partition as "1".
Similarly, the volume partition for /dev/sda is "0" (or you can leave the property empty).
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
Format: int32
| false |
| readOnly | boolean | readOnly here will force the ReadOnly setting in VolumeMounts.
Defaults to false.
More info: https://kubernetes.io/docs/concepts/storage/volumes#gcepersistentdisk
| false |
SpinApp.spec.volumes[index].gitRepo
back to parent
gitRepo represents a git repository at a particular revision.
Deprecated: GitRepo is deprecated. To provision a container with a git repo, mount an
EmptyDir into an InitContainer that clones the repo using git, then mount the EmptyDir
into the Pod’s container.
| Name | Type | Description | Required |
|---|
| repository | string | repository is the URL
| true |
| directory | string | directory is the target directory name.
Must not contain or start with '..'. If '.' is supplied, the volume directory will be the
git repository. Otherwise, if specified, the volume will contain the git repository in
the subdirectory with the given name.
| false |
| revision | string | revision is the commit hash for the specified revision.
| false |
SpinApp.spec.volumes[index].glusterfs
back to parent
glusterfs represents a Glusterfs mount on the host that shares a pod’s lifetime.
Deprecated: Glusterfs is deprecated and the in-tree glusterfs type is no longer supported.
More info: https://examples.k8s.io/volumes/glusterfs/README.md
| Name | Type | Description | Required |
|---|
| endpoints | string | endpoints is the endpoint name that details Glusterfs topology.
More info: https://examples.k8s.io/volumes/glusterfs/README.md#create-a-pod
| true |
| path | string | path is the Glusterfs volume path.
More info: https://examples.k8s.io/volumes/glusterfs/README.md#create-a-pod
| true |
| readOnly | boolean | readOnly here will force the Glusterfs volume to be mounted with read-only permissions.
Defaults to false.
More info: https://examples.k8s.io/volumes/glusterfs/README.md#create-a-pod
| false |
SpinApp.spec.volumes[index].hostPath
back to parent
hostPath represents a pre-existing file or directory on the host
machine that is directly exposed to the container. This is generally
used for system agents or other privileged things that are allowed
to see the host machine. Most containers will NOT need this.
More info: https://kubernetes.io/docs/concepts/storage/volumes#hostpath
| Name | Type | Description | Required |
|---|
| path | string | path of the directory on the host.
If the path is a symlink, it will follow the link to the real path.
More info: https://kubernetes.io/docs/concepts/storage/volumes#hostpath
| true |
| type | string | type for HostPath Volume
Defaults to ""
More info: https://kubernetes.io/docs/concepts/storage/volumes#hostpath
| false |
SpinApp.spec.volumes[index].image
back to parent
image represents an OCI object (a container image or artifact) pulled and mounted on the kubelet’s host machine.
The volume is resolved at pod startup depending on which PullPolicy value is provided:
- Always: the kubelet always attempts to pull the reference. Container creation will fail If the pull fails.
- Never: the kubelet never pulls the reference and only uses a local image or artifact. Container creation will fail if the reference isn’t present.
- IfNotPresent: the kubelet pulls if the reference isn’t already present on disk. Container creation will fail if the reference isn’t present and the pull fails.
The volume gets re-resolved if the pod gets deleted and recreated, which means that new remote content will become available on pod recreation.
A failure to resolve or pull the image during pod startup will block containers from starting and may add significant latency. Failures will be retried using normal volume backoff and will be reported on the pod reason and message.
The types of objects that may be mounted by this volume are defined by the container runtime implementation on a host machine and at minimum must include all valid types supported by the container image field.
The OCI object gets mounted in a single directory (spec.containers[].volumeMounts.mountPath) by merging the manifest layers in the same way as for container images.
The volume will be mounted read-only (ro) and non-executable files (noexec).
Sub path mounts for containers are not supported (spec.containers[].volumeMounts.subpath) before 1.33.
The field spec.securityContext.fsGroupChangePolicy has no effect on this volume type.
| Name | Type | Description | Required |
|---|
| pullPolicy | string | Policy for pulling OCI objects. Possible values are:
Always: the kubelet always attempts to pull the reference. Container creation will fail If the pull fails.
Never: the kubelet never pulls the reference and only uses a local image or artifact. Container creation will fail if the reference isn't present.
IfNotPresent: the kubelet pulls if the reference isn't already present on disk. Container creation will fail if the reference isn't present and the pull fails.
Defaults to Always if :latest tag is specified, or IfNotPresent otherwise.
| false |
| reference | string | Required: Image or artifact reference to be used.
Behaves in the same way as pod.spec.containers[*].image.
Pull secrets will be assembled in the same way as for the container image by looking up node credentials, SA image pull secrets, and pod spec image pull secrets.
More info: https://kubernetes.io/docs/concepts/containers/images
This field is optional to allow higher level config management to default or override
container images in workload controllers like Deployments and StatefulSets.
| false |
SpinApp.spec.volumes[index].iscsi
back to parent
iscsi represents an ISCSI Disk resource that is attached to a
kubelet’s host machine and then exposed to the pod.
More info: https://examples.k8s.io/volumes/iscsi/README.md
| Name | Type | Description | Required |
|---|
| iqn | string | iqn is the target iSCSI Qualified Name.
| true |
| lun | integer | lun represents iSCSI Target Lun number.
Format: int32
| true |
| targetPortal | string | targetPortal is iSCSI Target Portal. The Portal is either an IP or ip_addr:port if the port
is other than default (typically TCP ports 860 and 3260).
| true |
| chapAuthDiscovery | boolean | chapAuthDiscovery defines whether support iSCSI Discovery CHAP authentication
| false |
| chapAuthSession | boolean | chapAuthSession defines whether support iSCSI Session CHAP authentication
| false |
| fsType | string | fsType is the filesystem type of the volume that you want to mount.
Tip: Ensure that the filesystem type is supported by the host operating system.
Examples: "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
More info: https://kubernetes.io/docs/concepts/storage/volumes#iscsi
| false |
| initiatorName | string | initiatorName is the custom iSCSI Initiator Name.
If initiatorName is specified with iscsiInterface simultaneously, new iSCSI interface
: will be created for the connection.
| false |
| iscsiInterface | string | iscsiInterface is the interface Name that uses an iSCSI transport.
Defaults to 'default' (tcp).
Default: default
| false |
| portals | []string | portals is the iSCSI Target Portal List. The portal is either an IP or ip_addr:port if the port
is other than default (typically TCP ports 860 and 3260).
| false |
| readOnly | boolean | readOnly here will force the ReadOnly setting in VolumeMounts.
Defaults to false.
| false |
| secretRef | object | secretRef is the CHAP Secret for iSCSI target and initiator authentication
| false |
SpinApp.spec.volumes[index].iscsi.secretRef
back to parent
secretRef is the CHAP Secret for iSCSI target and initiator authentication
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].nfs
back to parent
nfs represents an NFS mount on the host that shares a pod’s lifetime
More info: https://kubernetes.io/docs/concepts/storage/volumes#nfs
| Name | Type | Description | Required |
|---|
| path | string | path that is exported by the NFS server.
More info: https://kubernetes.io/docs/concepts/storage/volumes#nfs
| true |
| server | string | server is the hostname or IP address of the NFS server.
More info: https://kubernetes.io/docs/concepts/storage/volumes#nfs
| true |
| readOnly | boolean | readOnly here will force the NFS export to be mounted with read-only permissions.
Defaults to false.
More info: https://kubernetes.io/docs/concepts/storage/volumes#nfs
| false |
SpinApp.spec.volumes[index].persistentVolumeClaim
back to parent
persistentVolumeClaimVolumeSource represents a reference to a
PersistentVolumeClaim in the same namespace.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#persistentvolumeclaims
| Name | Type | Description | Required |
|---|
| claimName | string | claimName is the name of a PersistentVolumeClaim in the same namespace as the pod using this volume.
More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#persistentvolumeclaims
| true |
| readOnly | boolean | readOnly Will force the ReadOnly setting in VolumeMounts.
Default false.
| false |
SpinApp.spec.volumes[index].photonPersistentDisk
back to parent
photonPersistentDisk represents a PhotonController persistent disk attached and mounted on kubelets host machine.
Deprecated: PhotonPersistentDisk is deprecated and the in-tree photonPersistentDisk type is no longer supported.
| Name | Type | Description | Required |
|---|
| pdID | string | pdID is the ID that identifies Photon Controller persistent disk
| true |
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
| false |
SpinApp.spec.volumes[index].portworxVolume
back to parent
portworxVolume represents a portworx volume attached and mounted on kubelets host machine.
Deprecated: PortworxVolume is deprecated. All operations for the in-tree portworxVolume type
are redirected to the pxd.portworx.com CSI driver when the CSIMigrationPortworx feature-gate
is on.
| Name | Type | Description | Required |
|---|
| volumeID | string | volumeID uniquely identifies a Portworx volume
| true |
| fsType | string | fSType represents the filesystem type to mount
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs". Implicitly inferred to be "ext4" if unspecified.
| false |
| readOnly | boolean | readOnly defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
SpinApp.spec.volumes[index].projected
back to parent
projected items for all in one resources secrets, configmaps, and downward API
| Name | Type | Description | Required |
|---|
| defaultMode | integer | defaultMode are the mode bits used to set permissions on created files by default.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
Directories within the path are not affected by this setting.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| sources | []object | sources is the list of volume projections. Each entry in this list
handles one source.
| false |
SpinApp.spec.volumes[index].projected.sources[index]
back to parent
Projection that may be projected along with other supported volume types.
Exactly one of these fields must be set.
| Name | Type | Description | Required |
|---|
| clusterTrustBundle | object | ClusterTrustBundle allows a pod to access the `.spec.trustBundle` field
of ClusterTrustBundle objects in an auto-updating file. Alpha, gated by the ClusterTrustBundleProjection feature gate. ClusterTrustBundle objects can either be selected by name, or by the
combination of signer name and a label selector. Kubelet performs aggressive normalization of the PEM contents written
into the pod filesystem. Esoteric PEM features such as inter-block
comments and block headers are stripped. Certificates are deduplicated.
The ordering of certificates within the file is arbitrary, and Kubelet
may change the order over time.
| false |
| configMap | object | configMap information about the configMap data to project
| false |
| downwardAPI | object | downwardAPI information about the downwardAPI data to project
| false |
| secret | object | secret information about the secret data to project
| false |
| serviceAccountToken | object | serviceAccountToken is information about the serviceAccountToken data to project
| false |
SpinApp.spec.volumes[index].projected.sources[index].clusterTrustBundle
back to parent
ClusterTrustBundle allows a pod to access the .spec.trustBundle field
of ClusterTrustBundle objects in an auto-updating file.
Alpha, gated by the ClusterTrustBundleProjection feature gate.
ClusterTrustBundle objects can either be selected by name, or by the
combination of signer name and a label selector.
Kubelet performs aggressive normalization of the PEM contents written
into the pod filesystem. Esoteric PEM features such as inter-block
comments and block headers are stripped. Certificates are deduplicated.
The ordering of certificates within the file is arbitrary, and Kubelet
may change the order over time.
| Name | Type | Description | Required |
|---|
| path | string | Relative path from the volume root to write the bundle.
| true |
| labelSelector | object | Select all ClusterTrustBundles that match this label selector. Only has
effect if signerName is set. Mutually-exclusive with name. If unset,
interpreted as "match nothing". If set but empty, interpreted as "match
everything".
| false |
| name | string | Select a single ClusterTrustBundle by object name. Mutually-exclusive
with signerName and labelSelector.
| false |
| optional | boolean | If true, don't block pod startup if the referenced ClusterTrustBundle(s)
aren't available. If using name, then the named ClusterTrustBundle is
allowed not to exist. If using signerName, then the combination of
signerName and labelSelector is allowed to match zero
ClusterTrustBundles.
| false |
| signerName | string | Select all ClusterTrustBundles that match this signer name.
Mutually-exclusive with name. The contents of all selected
ClusterTrustBundles will be unified and deduplicated.
| false |
SpinApp.spec.volumes[index].projected.sources[index].clusterTrustBundle.labelSelector
back to parent
Select all ClusterTrustBundles that match this label selector. Only has
effect if signerName is set. Mutually-exclusive with name. If unset,
interpreted as “match nothing”. If set but empty, interpreted as “match
everything”.
| Name | Type | Description | Required |
|---|
| matchExpressions | []object | matchExpressions is a list of label selector requirements. The requirements are ANDed.
| false |
| matchLabels | map[string]string | matchLabels is a map of {key,value} pairs. A single {key,value} in the matchLabels
map is equivalent to an element of matchExpressions, whose key field is "key", the
operator is "In", and the values array contains only "value". The requirements are ANDed.
| false |
SpinApp.spec.volumes[index].projected.sources[index].clusterTrustBundle.labelSelector.matchExpressions[index]
back to parent
A label selector requirement is a selector that contains values, a key, and an operator that
relates the key and values.
| Name | Type | Description | Required |
|---|
| key | string | key is the label key that the selector applies to.
| true |
| operator | string | operator represents a key's relationship to a set of values.
Valid operators are In, NotIn, Exists and DoesNotExist.
| true |
| values | []string | values is an array of string values. If the operator is In or NotIn,
the values array must be non-empty. If the operator is Exists or DoesNotExist,
the values array must be empty. This array is replaced during a strategic
merge patch.
| false |
SpinApp.spec.volumes[index].projected.sources[index].configMap
back to parent
configMap information about the configMap data to project
| Name | Type | Description | Required |
|---|
| items | []object | items if unspecified, each key-value pair in the Data field of the referenced
ConfigMap will be projected into the volume as a file whose name is the
key and content is the value. If specified, the listed keys will be
projected into the specified paths, and unlisted keys will not be
present. If a key is specified which is not present in the ConfigMap,
the volume setup will error unless it is marked optional. Paths must be
relative and may not contain the '..' path or start with '..'.
| false |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | optional specify whether the ConfigMap or its keys must be defined
| false |
SpinApp.spec.volumes[index].projected.sources[index].configMap.items[index]
back to parent
Maps a string key to a path within a volume.
| Name | Type | Description | Required |
|---|
| key | string | key is the key to project.
| true |
| path | string | path is the relative path of the file to map the key to.
May not be an absolute path.
May not contain the path element '..'.
May not start with the string '..'.
| true |
| mode | integer | mode is Optional: mode bits used to set permissions on this file.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
SpinApp.spec.volumes[index].projected.sources[index].downwardAPI
back to parent
downwardAPI information about the downwardAPI data to project
| Name | Type | Description | Required |
|---|
| items | []object | Items is a list of DownwardAPIVolume file
| false |
SpinApp.spec.volumes[index].projected.sources[index].downwardAPI.items[index]
back to parent
DownwardAPIVolumeFile represents information to create the file containing the pod field
| Name | Type | Description | Required |
|---|
| path | string | Required: Path is the relative path name of the file to be created. Must not be absolute or contain the '..' path. Must be utf-8 encoded. The first item of the relative path must not start with '..'
| true |
| fieldRef | object | Required: Selects a field of the pod: only annotations, labels, name, namespace and uid are supported.
| false |
| mode | integer | Optional: mode bits used to set permissions on this file, must be an octal value
between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| resourceFieldRef | object | Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, requests.cpu and requests.memory) are currently supported.
| false |
SpinApp.spec.volumes[index].projected.sources[index].downwardAPI.items[index].fieldRef
back to parent
Required: Selects a field of the pod: only annotations, labels, name, namespace and uid are supported.
| Name | Type | Description | Required |
|---|
| fieldPath | string | Path of the field to select in the specified API version.
| true |
| apiVersion | string | Version of the schema the FieldPath is written in terms of, defaults to "v1".
| false |
SpinApp.spec.volumes[index].projected.sources[index].downwardAPI.items[index].resourceFieldRef
back to parent
Selects a resource of the container: only resources limits and requests
(limits.cpu, limits.memory, requests.cpu and requests.memory) are currently supported.
| Name | Type | Description | Required |
|---|
| resource | string | Required: resource to select
| true |
| containerName | string | Container name: required for volumes, optional for env vars
| false |
| divisor | int or string | Specifies the output format of the exposed resources, defaults to "1"
| false |
SpinApp.spec.volumes[index].projected.sources[index].secret
back to parent
secret information about the secret data to project
| Name | Type | Description | Required |
|---|
| items | []object | items if unspecified, each key-value pair in the Data field of the referenced
Secret will be projected into the volume as a file whose name is the
key and content is the value. If specified, the listed keys will be
projected into the specified paths, and unlisted keys will not be
present. If a key is specified which is not present in the Secret,
the volume setup will error unless it is marked optional. Paths must be
relative and may not contain the '..' path or start with '..'.
| false |
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
| optional | boolean | optional field specify whether the Secret or its key must be defined
| false |
SpinApp.spec.volumes[index].projected.sources[index].secret.items[index]
back to parent
Maps a string key to a path within a volume.
| Name | Type | Description | Required |
|---|
| key | string | key is the key to project.
| true |
| path | string | path is the relative path of the file to map the key to.
May not be an absolute path.
May not contain the path element '..'.
May not start with the string '..'.
| true |
| mode | integer | mode is Optional: mode bits used to set permissions on this file.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
SpinApp.spec.volumes[index].projected.sources[index].serviceAccountToken
back to parent
serviceAccountToken is information about the serviceAccountToken data to project
| Name | Type | Description | Required |
|---|
| path | string | path is the path relative to the mount point of the file to project the
token into.
| true |
| audience | string | audience is the intended audience of the token. A recipient of a token
must identify itself with an identifier specified in the audience of the
token, and otherwise should reject the token. The audience defaults to the
identifier of the apiserver.
| false |
| expirationSeconds | integer | expirationSeconds is the requested duration of validity of the service
account token. As the token approaches expiration, the kubelet volume
plugin will proactively rotate the service account token. The kubelet will
start trying to rotate the token if the token is older than 80 percent of
its time to live or if the token is older than 24 hours.Defaults to 1 hour
and must be at least 10 minutes.
Format: int64
| false |
SpinApp.spec.volumes[index].quobyte
back to parent
quobyte represents a Quobyte mount on the host that shares a pod’s lifetime.
Deprecated: Quobyte is deprecated and the in-tree quobyte type is no longer supported.
| Name | Type | Description | Required |
|---|
| registry | string | registry represents a single or multiple Quobyte Registry services
specified as a string as host:port pair (multiple entries are separated with commas)
which acts as the central registry for volumes
| true |
| volume | string | volume is a string that references an already created Quobyte volume by name.
| true |
| group | string | group to map volume access to
Default is no group
| false |
| readOnly | boolean | readOnly here will force the Quobyte volume to be mounted with read-only permissions.
Defaults to false.
| false |
| tenant | string | tenant owning the given Quobyte volume in the Backend
Used with dynamically provisioned Quobyte volumes, value is set by the plugin
| false |
| user | string | user to map volume access to
Defaults to serivceaccount user
| false |
SpinApp.spec.volumes[index].rbd
back to parent
rbd represents a Rados Block Device mount on the host that shares a pod’s lifetime.
Deprecated: RBD is deprecated and the in-tree rbd type is no longer supported.
More info: https://examples.k8s.io/volumes/rbd/README.md
| Name | Type | Description | Required |
|---|
| image | string | image is the rados image name.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
| true |
| monitors | []string | monitors is a collection of Ceph monitors.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
| true |
| fsType | string | fsType is the filesystem type of the volume that you want to mount.
Tip: Ensure that the filesystem type is supported by the host operating system.
Examples: "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
More info: https://kubernetes.io/docs/concepts/storage/volumes#rbd
| false |
| keyring | string | keyring is the path to key ring for RBDUser.
Default is /etc/ceph/keyring.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
Default: /etc/ceph/keyring
| false |
| pool | string | pool is the rados pool name.
Default is rbd.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
Default: rbd
| false |
| readOnly | boolean | readOnly here will force the ReadOnly setting in VolumeMounts.
Defaults to false.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
| false |
| secretRef | object | secretRef is name of the authentication secret for RBDUser. If provided
overrides keyring.
Default is nil.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
| false |
| user | string | user is the rados user name.
Default is admin.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
Default: admin
| false |
SpinApp.spec.volumes[index].rbd.secretRef
back to parent
secretRef is name of the authentication secret for RBDUser. If provided
overrides keyring.
Default is nil.
More info: https://examples.k8s.io/volumes/rbd/README.md#how-to-use-it
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].scaleIO
back to parent
scaleIO represents a ScaleIO persistent volume attached and mounted on Kubernetes nodes.
Deprecated: ScaleIO is deprecated and the in-tree scaleIO type is no longer supported.
| Name | Type | Description | Required |
|---|
| gateway | string | gateway is the host address of the ScaleIO API Gateway.
| true |
| secretRef | object | secretRef references to the secret for ScaleIO user and other
sensitive information. If this is not provided, Login operation will fail.
| true |
| system | string | system is the name of the storage system as configured in ScaleIO.
| true |
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs".
Default is "xfs".
Default: xfs
| false |
| protectionDomain | string | protectionDomain is the name of the ScaleIO Protection Domain for the configured storage.
| false |
| readOnly | boolean | readOnly Defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
| sslEnabled | boolean | sslEnabled Flag enable/disable SSL communication with Gateway, default false
| false |
| storageMode | string | storageMode indicates whether the storage for a volume should be ThickProvisioned or ThinProvisioned.
Default is ThinProvisioned.
Default: ThinProvisioned
| false |
| storagePool | string | storagePool is the ScaleIO Storage Pool associated with the protection domain.
| false |
| volumeName | string | volumeName is the name of a volume already created in the ScaleIO system
that is associated with this volume source.
| false |
SpinApp.spec.volumes[index].scaleIO.secretRef
back to parent
secretRef references to the secret for ScaleIO user and other
sensitive information. If this is not provided, Login operation will fail.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].secret
back to parent
secret represents a secret that should populate this volume.
More info: https://kubernetes.io/docs/concepts/storage/volumes#secret
| Name | Type | Description | Required |
|---|
| defaultMode | integer | defaultMode is Optional: mode bits used to set permissions on created files by default.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values
for mode bits. Defaults to 0644.
Directories within the path are not affected by this setting.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
| items | []object | items If unspecified, each key-value pair in the Data field of the referenced
Secret will be projected into the volume as a file whose name is the
key and content is the value. If specified, the listed keys will be
projected into the specified paths, and unlisted keys will not be
present. If a key is specified which is not present in the Secret,
the volume setup will error unless it is marked optional. Paths must be
relative and may not contain the '..' path or start with '..'.
| false |
| optional | boolean | optional field specify whether the Secret or its keys must be defined
| false |
| secretName | string | secretName is the name of the secret in the pod's namespace to use.
More info: https://kubernetes.io/docs/concepts/storage/volumes#secret
| false |
SpinApp.spec.volumes[index].secret.items[index]
back to parent
Maps a string key to a path within a volume.
| Name | Type | Description | Required |
|---|
| key | string | key is the key to project.
| true |
| path | string | path is the relative path of the file to map the key to.
May not be an absolute path.
May not contain the path element '..'.
May not start with the string '..'.
| true |
| mode | integer | mode is Optional: mode bits used to set permissions on this file.
Must be an octal value between 0000 and 0777 or a decimal value between 0 and 511.
YAML accepts both octal and decimal values, JSON requires decimal values for mode bits.
If not specified, the volume defaultMode will be used.
This might be in conflict with other options that affect the file
mode, like fsGroup, and the result can be other mode bits set.
Format: int32
| false |
SpinApp.spec.volumes[index].storageos
back to parent
storageOS represents a StorageOS volume attached and mounted on Kubernetes nodes.
Deprecated: StorageOS is deprecated and the in-tree storageos type is no longer supported.
| Name | Type | Description | Required |
|---|
| fsType | string | fsType is the filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
| false |
| readOnly | boolean | readOnly defaults to false (read/write). ReadOnly here will force
the ReadOnly setting in VolumeMounts.
| false |
| secretRef | object | secretRef specifies the secret to use for obtaining the StorageOS API
credentials. If not specified, default values will be attempted.
| false |
| volumeName | string | volumeName is the human-readable name of the StorageOS volume. Volume
names are only unique within a namespace.
| false |
| volumeNamespace | string | volumeNamespace specifies the scope of the volume within StorageOS. If no
namespace is specified then the Pod's namespace will be used. This allows the
Kubernetes name scoping to be mirrored within StorageOS for tighter integration.
Set VolumeName to any name to override the default behaviour.
Set to "default" if you are not using namespaces within StorageOS.
Namespaces that do not pre-exist within StorageOS will be created.
| false |
SpinApp.spec.volumes[index].storageos.secretRef
back to parent
secretRef specifies the secret to use for obtaining the StorageOS API
credentials. If not specified, default values will be attempted.
| Name | Type | Description | Required |
|---|
| name | string | Name of the referent.
This field is effectively required, but due to backwards compatibility is
allowed to be empty. Instances of this type with an empty value here are
almost certainly wrong.
More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
Default:
| false |
SpinApp.spec.volumes[index].vsphereVolume
back to parent
vsphereVolume represents a vSphere volume attached and mounted on kubelets host machine.
Deprecated: VsphereVolume is deprecated. All operations for the in-tree vsphereVolume type
are redirected to the csi.vsphere.vmware.com CSI driver.
| Name | Type | Description | Required |
|---|
| volumePath | string | volumePath is the path that identifies vSphere volume vmdk
| true |
| fsType | string | fsType is filesystem type to mount.
Must be a filesystem type supported by the host operating system.
Ex. "ext4", "xfs", "ntfs". Implicitly inferred to be "ext4" if unspecified.
| false |
| storagePolicyID | string | storagePolicyID is the storage Policy Based Management (SPBM) profile ID associated with the StoragePolicyName.
| false |
| storagePolicyName | string | storagePolicyName is the storage Policy Based Management (SPBM) profile name.
| false |
SpinApp.status
back to parent
SpinAppStatus defines the observed state of SpinApp
| Name | Type | Description | Required |
|---|
| readyReplicas | integer | Represents the current number of active replicas on the application deployment.
Format: int32
| true |
| activeScheduler | string | ActiveScheduler is the name of the scheduler that is currently scheduling this SpinApp.
| false |
| conditions | []object | Represents the observations of a SpinApps's current state.
SpinApp.status.conditions.type are: "Available" and "Progressing"
SpinApp.status.conditions.status are one of True, False, Unknown.
SpinApp.status.conditions.reason the value should be a CamelCase string and producers of specific
condition types may define expected values and meanings for this field, and whether the values
are considered a guaranteed API.
SpinApp.status.conditions.Message is a human readable message indicating details about the transition.
For further information see: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#typical-status-properties
| false |
SpinApp.status.conditions[index]
back to parent
Condition contains details for one aspect of the current state of this API Resource.
| Name | Type | Description | Required |
|---|
| lastTransitionTime | string | lastTransitionTime is the last time the condition transitioned from one status to another.
This should be when the underlying condition changed. If that is not known, then using the time when the API field changed is acceptable.
Format: date-time
| true |
| message | string | message is a human readable message indicating details about the transition.
This may be an empty string.
| true |
| reason | string | reason contains a programmatic identifier indicating the reason for the condition's last transition.
Producers of specific condition types may define expected values and meanings for this field,
and whether the values are considered a guaranteed API.
The value should be a CamelCase string.
This field may not be empty.
| true |
| status | enum | status of the condition, one of True, False, Unknown.
Enum: True, False, Unknown
| true |
| type | string | type of condition in CamelCase or in foo.example.com/CamelCase.
| true |
| observedGeneration | integer | observedGeneration represents the .metadata.generation that the condition was set based upon.
For instance, if .metadata.generation is currently 12, but the .status.conditions[x].observedGeneration is 9, the condition is out of date
with respect to the current state of the instance.
Format: int64
Minimum: 0
| false |
4.2 - SpinAppExecutor
Custom Resource Definition (CRD) reference for SpinAppExecutor
Resource Types:
SpinAppExecutor
SpinAppExecutor is the Schema for the spinappexecutors API
| Name | Type | Description | Required |
|---|
| apiVersion | string | core.spinkube.dev/v1alpha1 | true |
| kind | string | SpinAppExecutor | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the `metadata` field. | true |
| spec | object | SpinAppExecutorSpec defines the desired state of SpinAppExecutor
| false |
| status | object | SpinAppExecutorStatus defines the observed state of SpinAppExecutor
| false |
SpinAppExecutor.spec
back to parent
SpinAppExecutorSpec defines the desired state of SpinAppExecutor
| Name | Type | Description | Required |
|---|
| createDeployment | boolean | CreateDeployment specifies whether the Executor wants the SpinKube operator
to create a deployment for the application or if it will be realized externally.
| true |
| deploymentConfig | object | DeploymentConfig specifies how the deployment should be configured when
createDeployment is true.
| false |
SpinAppExecutor.spec.deploymentConfig
back to parent
DeploymentConfig specifies how the deployment should be configured when
createDeployment is true.
| Name | Type | Description | Required |
|---|
| caCertSecret | string | CACertSecret specifies the name of the secret containing the CA
certificates to be mounted to the deployment.
| false |
| installDefaultCACerts | boolean | InstallDefaultCACerts specifies whether the default CA
certificate bundle should be generated. When set a new secret
will be created containing the certificates. If no secret name is
defined in `CACertSecret` the secret name will be `spin-ca`.
| false |
| otel | object | Otel provides Kubernetes Bindings to Otel Variables.
| false |
| runtimeClassName | string | RuntimeClassName is the runtime class name that should be used by pods created
as part of a deployment. This should only be defined when SpintainerImage is not defined.
| false |
| spinImage | string | SpinImage points to an image that will run Spin in a container to execute
your SpinApp. This is an alternative to using the shim to execute your
SpinApp. This should only be defined when RuntimeClassName is not
defined. When specified, application images must be available without
authentication.
| false |
SpinAppExecutor.spec.deploymentConfig.otel
back to parent
Otel provides Kubernetes Bindings to Otel Variables.
| Name | Type | Description | Required |
|---|
| exporter_otlp_endpoint | string | ExporterOtlpEndpoint configures the default combined otlp endpoint for sending telemetry
| false |
| exporter_otlp_logs_endpoint | string | ExporterOtlpLogsEndpoint configures the logs-specific otlp endpoint
| false |
| exporter_otlp_metrics_endpoint | string | ExporterOtlpMetricsEndpoint configures the metrics-specific otlp endpoint
| false |
| exporter_otlp_traces_endpoint | string | ExporterOtlpTracesEndpoint configures the trace-specific otlp endpoint
| false |
4.3 - CLI Reference
Spin Plugin kube CLI Reference.
spin kube completion
spin kube completion --help
Generate the autocompletion script for kube for the specified shell.
See each sub-command's help for details on how to use the generated script.
Usage:
kube completion [command]
Available Commands:
bash Generate the autocompletion script for bash
fish Generate the autocompletion script for fish
powershell Generate the autocompletion script for powershell
zsh Generate the autocompletion script for zsh
Flags:
-h, --help help for completion
spin kube completion bash
spin kube completion bash --help
Generate the autocompletion script for the bash shell.
This script depends on the 'bash-completion' package.
If it is not installed already, you can install it via your OS's package manager.
To load completions in your current shell session:
source <(kube completion bash)
To load completions for every new session, execute once:
#### Linux:
kube completion bash > /etc/bash_completion.d/kube
#### macOS:
kube completion bash > $(brew --prefix)/etc/bash_completion.d/kube
You will need to start a new shell for this setup to take effect.
Usage:
kube completion bash
Flags:
-h, --help help for bash
--no-descriptions disable completion descriptions
spin kube completion fish
spin kube completion fish --help
Generate the autocompletion script for the fish shell.
To load completions in your current shell session:
kube completion fish | source
To load completions for every new session, execute once:
kube completion fish > ~/.config/fish/completions/kube.fish
You will need to start a new shell for this setup to take effect.
Usage:
kube completion fish [flags]
Flags:
-h, --help help for fish
--no-descriptions disable completion descriptions
spin kube completion powershell
spin kube completion powershell --help
Generate the autocompletion script for powershell.
To load completions in your current shell session:
kube completion powershell | Out-String | Invoke-Expression
To load completions for every new session, add the output of the above command
to your powershell profile.
Usage:
kube completion powershell [flags]
Flags:
-h, --help help for powershell
--no-descriptions disable completion descriptions
spin kube completion zsh
spin kube completion zsh --help
Generate the autocompletion script for the zsh shell.
If shell completion is not already enabled in your environment you will need
to enable it. You can execute the following once:
echo "autoload -U compinit; compinit" >> ~/.zshrc
To load completions in your current shell session:
source <(kube completion zsh)
To load completions for every new session, execute once:
#### Linux:
kube completion zsh > "${fpath[1]}/_kube"
#### macOS:
kube completion zsh > $(brew --prefix)/share/zsh/site-functions/_kube
You will need to start a new shell for this setup to take effect.
Usage:
kube completion zsh [flags]
Flags:
-h, --help help for zsh
--no-descriptions disable completion descriptions
spin kube help
spin kube --help
Manage apps running on Kubernetes
Usage:
kube [command]
Available Commands:
completion Generate the autocompletion script for the specified shell
help Help about any command
scaffold scaffold SpinApp manifest
version Display version information
Flags:
-h, --help help for kube
--kubeconfig string the path to the kubeconfig file
-n, --namespace string the namespace scope
-v, --version version for kube
spin kube scaffold
spin kube scaffold --help
scaffold SpinApp manifest
Usage:
kube scaffold [flags]
Flags:
--autoscaler string The autoscaler to use. Valid values are 'hpa' and 'keda'
--autoscaler-target-cpu-utilization int32 The target CPU utilization percentage to maintain across all pods (default 60)
--autoscaler-target-memory-utilization int32 The target memory utilization percentage to maintain across all pods (default 60)
--cpu-limit string The maximum amount of CPU resource units the Spin application is allowed to use
--cpu-request string The amount of CPU resource units requested by the Spin application. Used to determine which node the Spin application will run on
--executor string The executor used to run the Spin application (default "containerd-shim-spin")
-f, --from string Reference in the registry of the Spin application
-h, --help help for scaffold
-s, --image-pull-secret strings secrets in the same namespace to use for pulling the image
--max-replicas int32 Maximum number of replicas for the spin app. Autoscaling must be enabled to use this flag (default 3)
--memory-limit string The maximum amount of memory the Spin application is allowed to use
--memory-request string The amount of memory requested by the Spin application. Used to determine which node the Spin application will run on
-o, --out string path to file to write manifest yaml
-r, --replicas int32 Minimum number of replicas for the spin app (default 2)
-c, --runtime-config-file string path to runtime config file
spin kube version
5 - Miscellaneous
Documentation that we can’t find a more organized place for. Like that drawer in your kitchen with the scissors, batteries, duct tape, and other junk.
5.1 - Compatibility
A list of compatible Kubernetes distributions and platforms for running SpinKube.
See the following list of compatible Kubernetes distributions and platforms for running the Spin
Operator:
Disclaimer: Please note that this is a working list of compatible Kubernetes distributions and
platforms. For managed Kubernetes services, it’s important to be aware that cloud providers may
choose to discontinue support for specific dependencies, such as container runtimes. While we
strive to maintain the accuracy of this documentation, it is ultimately your responsibility to
verify with your Kubernetes provider whether the required dependencies are still supported.
How to validate Spin Operator Compatibility
If you would like to validate Spin Operator’s compatibility with a new specific Kubernetes
distribution or platform or simply test one of the platforms listed above yourself, follow these
steps for validation:
Install the Spin Operator: Begin by installing the Spin Operator within the Kubernetes
cluster. This involves deploying the necessary dependencies and the Spin Operator itself. (See
Installing with Helm)
Create, Package, and Deploy a Spin App: Proceed by creating a Spin App, packaging it, and
successfully deploying it within the Kubernetes environment. (See Package and Deploy Spin
Apps)
Invoke the Spin App: Once the Spin App is deployed, ensure at least one request was
successfully served by the Spin App.
Container Runtime Constraints
The Spin Operator requires the target nodes that would run Spin applications to support containerd
version 1.6.26+ or
1.7.7+.
Use the kubectl get nodes -o wide command to see which container runtime is installed per node:
# Inspect container runtimes per node
kubectl get nodes -o wide
NAME STATUS VERSION OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
generalnp-vmss000000 Ready v1.27.9 Ubuntu 22.04.4 LTS 5.15.0-1056-azure containerd://1.7.7-1
generalnp-vmss000001 Ready v1.27.9 Ubuntu 22.04.4 LTS 5.15.0-1056-azure containerd://1.7.7-1
generalnp-vmss000002 Ready v1.27.9 Ubuntu 22.04.4 LTS 5.15.0-1056-azure containerd://1.7.7-1
5.2 - Integrations
A high level overview of the SpinKube integrations.
SpinKube Integrations
KEDA
Kubernetes Event-Driven Autoscaling (KEDA) provides event-driven autoscaling for
Kubernetes workloads. It allows Kubernetes to automatically scale applications in response to
external events such as messages in a queue, enabling more efficient resource utilization and
responsive scaling based on actual demand, rather than static metrics. KEDA serves as a bridge
between Kubernetes and various event sources, making it easier to scale applications dynamically in
a cloud-native environment. If you would like to see how SpinKube integrates with KEDA, please read
the “Scaling With KEDA” tutorial which deploys a SpinApp and the
KEDA ScaledObject instance onto a cluster. The tutorial also uses Bombardier to generate traffic to
test how well KEDA scales our SpinApp.
Rancher Desktop
The release of Rancher Desktop
1.13.0
comes with basic support for running WebAssembly (Wasm) containers and deploying them to Kubernetes.
Rancher Desktop by SUSE, is an open-source application that provides all the essentials to work with
containers and Kubernetes on your desktop. If you would like to see how SpinKube integrates with
Rancher Desktop, please read the “Integrating With Rancher Desktop” tutorial which walks through the steps of installing the necessary
components for SpinKube (including the CertManager for SSL, CRDs and the Runtime Class Manager
using Helm charts). The tutorial then demonstrates how to create a simple Spin JavaScript
application and deploys the application within Rancher Desktop’s local cluster.
5.3 - Spintainer Executor
An overview of what the Spintainer Executor does and how it can be used.
The Spintainer Executor
The Spintainer (a play on the words Spin and container) executor is a SpinAppExecutor that runs Spin applications directly in a container rather than via the shim. This is useful for a number of reasons:
- Provides the flexibility to:
- Use any Spin version you want.
- Use any custom triggers or plugins you want.
- Allows you to use SpinKube even if you don’t have the cluster permissions to install the shim.
Note: We recommend using the shim for most use cases. The spintainer executor is best saved as a workaround.
How to create a spintainer executor
The following is some sample configuration for a spintainer executor:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinAppExecutor
metadata:
name: spintainer
spec:
createDeployment: true
deploymentConfig:
installDefaultCACerts: true
spinImage: ghcr.io/fermyon/spin:v2.7.0
Save this into a file named spintainer-executor.yaml and then apply it to the cluster.
kubectl apply -f spintainer-executor.yaml
How to use a spintainer executor
To use the spintainer executor you must reference it as the executor of your SpinApp.
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: simple-spinapp
spec:
image: "ghcr.io/spinkube/containerd-shim-spin/examples/spin-rust-hello:v0.13.0"
replicas: 1
executor: spintainer
How the spintainer executor works
The spintainer executor executes your Spin application in a container created from the image specified by .spec.deploymentConfig.spinImage. The container image must have a Spin binary be the entrypoint of the container. It will be started with the following args.
up --listen {spin-operator-defined-port} -f {spin-operator-defined-image} --runtime-config-file {spin-operator-defined-config-file}
For ease of use you can use the images published by the Spin project here. Alternatively you can craft images for your own unique need.
5.4 - Upgrading to v0.4.0
Instructions on how to navigate the breaking changes v0.4.0 introduces.
Spin Operator v0.4.0 introduces a breaking API change. The SpinApp and SpinAppExecutor are moving from the spinoperator.dev to spinkube.dev domains. This is a breaking change and therefore requires a re-install of the Spin Operator when upgrading to v0.4.0.
Migration steps
Uninstall any existing SpinApps.
Note: Back em’ up! TODO
kubectl get spinapps.core.spinoperator.dev -o yaml > spinapps.yaml
kubectl delete spinapp.core.spinoperator.dev --all
Uninstall any existing SpinAppExecutors.
kubectl delete spinappexecutor.core.spinoperator.dev --all
Uninstall the old Spin Operator.
Note: If you used a different release name or namespace when installing the Spin Operator you’ll have to adjust the command accordingly. Alternatively, if you used something other than Helm to install the Spin Operator, you’ll need to uninstall it following whatever approach you used to install it.
helm uninstall spin-operator --namespace spin-operator
Uninstall the old CRDs.
kubectl delete crd spinapps.core.spinoperator.dev
kubectl delete crd spinappexecutors.core.spinoperator.dev
Modify your SpinApps to use the new apiVersion.
Now you’ll need to modify the apiVersion in your SpinApps, replacing core.spinoperator.dev/v1alpha1 with core.spinkube.dev/v1alpha1.
Note: If you don’t have your SpinApps tracked in source code somewhere than you will have backed up the SpinApps in your cluster to a file named spinapps.yaml in step 1. If you did this then you need to replace the apiVersion in the spinapps.yaml file. Here’s a command that can help with that:
sed 's|apiVersion: core.spinoperator.dev/v1alpha1|apiVersion: core.spinkube.dev/v1alpha1|g' spinapps.yaml > modified-spinapps.yaml
Install the new CRDs.
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.4.0/spin-operator.crds.yaml
Re-install the SpinAppExecutor.
kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.4.0/spin-operator.shim-executor.yaml
If you had other executors you’ll need to install them too.
Install the new Spin Operator.
# Install Spin Operator with Helm
helm install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.4.0 \
--wait \
oci://ghcr.io/spinkube/charts/spin-operator
Re-apply your modified SpinApps.
Follow whatever pattern you normally follow to get your SpinApps in the cluster e.g. Kubectl, Flux, Helm, etc.
Note: If you backed up your SpinApps in step 1, you can re-apply them using the command below:
kubectl apply -f modified-spinapps.yaml
Upgrade your spin kube plugin.
If you’re using the spin kube plugin you’ll need to upgrade it to the new version so that the scaffolded apps are still valid.
spin plugins upgrade kube
6 - How to get involved
How to contribute to the SpinKube project.
SpinKube is an open source community-driven project. You can contribute in many ways, either to the
project or to the wider community.
Join our bi-weekly community calls to connect with the team and other contributors. These calls are a great opportunity to listen in, ask questions, or share your ideas!
Slack
Connect with the community on Slack for real-time discussions and updates:
visit the #spinkube channel on the CNCF
Slack.
We look forward to seeing you there!
6.1 - Advice for new contributors
Are you a contributor and not sure what to do? Want to help but just don’t know how to get started? This is the section for you.
This page contains more general advice on ways you can contribute to SpinKube, and how to approach
that.
If you are looking for a reference on the details of making code contributions, see the Writing
code documentation.
First steps
Start with these steps to be successful as a contributor to SpinKube.
Join the conversation
It can be argued that collaboration and communication are the most crucial aspects of open source
development. Gaining consensus on the direction of the project, and that your work is aligned with
that direction, is key to getting your work accepted. This is why it is important to join the
conversation early and often.
To join the conversation, visit the #spinkube channel on the CNCF
Slack.
Read the documentation
The SpinKube documentation is a great place to start. It contains information on how to get started
with the project, how to contribute, and how to use the project. The documentation is also a great
place to find information on the project’s architecture and design.
SpinKube’s documentation is great but it is not perfect. If you find something that is unclear or
incorrect, please submit a pull request to fix it. See the guide on writing documentation for more information.
Triage issues
If an issue reports a bug, try and reproduce it. If you can reproduce it and it seems valid, make a
note that you confirmed the bug. Make sure the issue is labeled properly. If you cannot reproduce
the bug, ask the reporter for more information.
Write tests
Consider writing a test for the bug’s behavior, even if you don’t fix the bug itself.
issues labeled good first issue are a great place to start. These issues are specifically tagged
as being good for new contributors to work on.
Guidelines
As a newcomer on a large project, it’s easy to experience frustration. Here’s some advice to make
your work on SpinKube more useful and rewarding.
Pick a subject area that you care about, that you are familiar with, or that you want to learn about
You don’t already have to be an expert on the area you want to work on; you become an expert through
your ongoing contributions to the code.
Start small
It’s easier to get feedback on a little issue than on a big one, especially as a new contributor;
the maintainters are more likely to have time to review a small change.
If you’re going to engage in a big task, make sure that your idea has support first
This means getting someone else to confirm that a bug is real before you fix the issue, and ensuring
that there’s consensus on a proposed feature before you go implementing it.
Be bold! Leave feedback!
Sometimes it can be scary to put your opinion out to the world and say “this issue is correct” or
“this patch needs work”, but it’s the only way the project moves forward. The contributions of the
broad SpinKube community ultimately have a much greater impact than that of any one person. We can’t
do it without you!
Err on the side of caution when marking things ready for review
If you’re really not certain if a pull request is ready for review, don’t mark it as such. Leave a
comment instead, letting others know your thoughts. If you’re mostly certain, but not completely
certain, you might also try asking on Slack
to see if someone else can confirm your suspicions.
Wait for feedback, and respond to feedback that you receive
Focus on one or two issues, see them through from start to finish, and repeat. The shotgun approach
of taking on lots of issues and letting some fall by the wayside ends up doing more harm than good.
Be rigorous
When we say “this pull request must have documentation and tests”, we mean it. If a patch doesn’t
have documentation and tests, there had better be a good reason. Arguments like “I couldn’t find any
existing tests of this feature” don’t carry much weight; while it may be true, that means you have
the extra-important job of writing the very first tests for that feature, not that you get a pass
from writing tests altogether.
Be patient
It’s not always easy for your issue or your patch to be reviewed quickly. This isn’t personal. There
are a lot of issues and pull requests to get through.
Keeping your patch up to date is important. Review the pull request on GitHub to ensure that you’ve
addressed all review comments.
6.2 - Writing code
Fix a bug, or add a new feature. You can make a pull request and see your code in the next version of SpinKube!
Interested in giving back to the community a little? Maybe you’ve found a bug in SpinKube that you’d
like to see fixed, or maybe there’s a small feature you want added.
Contributing back to SpinKube itself is the best way to see your own concerns addressed. This may
seem daunting at first, but it’s a well-traveled path with documentation, tooling, and a community
to support you. We’ll walk you through the entire process, so you can learn by example.
Who’s this tutorial for?
For this tutorial, we expect that you have at least a basic understanding of how SpinKube works.
This means you should be comfortable going through the existing tutorials on deploying your first
app to SpinKube. It is also worthwhile learning a bit of Rust, since many of SpinKube’s projects are
written in Rust. If you don’t, Learn Rust is a great place to
start.
Those of you who are unfamiliar with git and GitHub will find that this tutorial and its links
include just enough information to get started. However, you’ll probably want to read some more
about these different tools if you plan on contributing to SpinKube regularly.
For the most part though, this tutorial tries to explain as much as possible, so that it can be of
use to the widest audience.
Code of Conduct
As a contributor, you can help us keep the SpinKube community open and inclusive. Please read and
follow our Code of Conduct.
Install git
For this tutorial, you’ll need Git installed to download the current development version of SpinKube
and to generate a branch for the changes you make.
To check whether or not you have Git installed, enter git into the command line. If you get
messages saying that this command could not be found, you’ll have to download and install it. See
Git’s download page for more information.
If you’re not that familiar with Git, you can always find out more about its commands (once it’s
installed) by typing git help into the command line.
Fork the repository
SpinKube is hosted on GitHub, and you’ll need a GitHub account to contribute. If you don’t have one,
you can sign up for free at GitHub.
SpinKube’s repositories are organized under the spinframework GitHub
organization. Once you have an account, fork one of the repositories
by visiting the repository’s page and clicking “Fork” in the upper right corner.
Then, from the command line, clone your fork of the repository. For example, if you forked the
spin-operator repository, you would run:
git clone https://github.com/YOUR-USERNAME/spin-operator.git
Read the README
Each repository in the SpinKube organization has a README file that explains what the project does
and how to get started. This is a great place to start, as it will give you an overview of the
project and how to run the test suite.
Run the test suite
When contributing to a project, it’s very important that your code changes don’t introduce bugs. One
way to check that the project still works after you make your changes is by running the project’s
test suite. If all the tests still pass, then you can be reasonably sure that your changes work and
haven’t broken other parts of the project. If you’ve never run the project’s test suite before, it’s
a good idea to run it once beforehand to get familiar with its output.
Most projects have a command to run the test suite. This is usually something like make test or
cargo test. Check the project’s README file for instructions on how to run the test suite. If
you’re not sure, you can always ask for help in the #spinkube channel on
Slack.
Find an issue to work on
If you’re not sure where to start, you can look for issues labeled good first issue in the
repository you’re interested in. These issues are often much simpler in nature and specifically
tagged as being good for new contributors to work on.
Create a branch
Before making any changes, create a new branch for the issue:
git checkout -b issue-123
Choose any name that you want for the branch. issue-123 is an example. All changes made in this
branch will be specific to the issue and won’t affect the main copy of the code that we cloned
earlier.
Write some tests for your issue
If you’re fixing a bug, write a test (or multiple tests) that reproduces the bug. If you’re adding a
new feature, write a test that verifies the feature works as expected. This will help ensure that
your changes work as expected and don’t break other parts of the project.
Confirm the tests fail
Now that we’ve written a test, we need to confirm that it fails. This is important because it
verifies that the test is actually testing what we think it is. If the test passes, then it’s not
actually testing the issue we’re trying to fix.
To run the test suite, refer to the project’s README or reach out on
Slack.
Make the changes
Now that we have a failing test, we can make the changes to the code to fix the issue. This is the
fun part! Use your favorite text editor to make the changes.
Confirm the tests pass
After making the changes, run the test suite again to confirm that the tests pass. If the tests
pass, then you can be reasonably sure that your changes work as expected.
Once you’ve verified that your changes and test are working correctly, it’s a good idea to run the
entire test suite to verify that your change hasn’t introduced any bugs into other areas of the
project. While successfully passing the entire test suite doesn’t guarantee your code is bug free,
it does help identify many bugs and regressions that might otherwise go unnoticed.
Commit your changes
Once you’ve made your changes and confirmed that the tests pass, commit your changes to your branch:
git add .
git commit -m "Fix issue 123"
Push your changes
Now that you’ve committed your changes to your branch, push your branch to your fork on GitHub:
git push origin issue-123
Create a pull request
Once you’ve pushed your changes to your fork on GitHub, you can create a pull request. This is a
request to merge your changes into the main copy of the code. To create a pull request, visit your
fork on GitHub and click the “New pull request” button.
Write documentation
If your changes introduce new features or change existing behavior, it’s important to update the
documentation. This helps other contributors understand your changes and how to use them.
See the guide on writing documentation for more information.
Next steps
Congratulations! You’ve made a contribution to SpinKube.
After a pull request has been submitted, it needs to be reviewed by a maintainer. Reach out on the
#spinkube channel on the CNCF Slack to ask
for a review.
6.3 - Writing documentation
Our goal is to keep the documentation informative and thorough. You can help to improve the documentation and keep it relevant as the project evolves.
We place high importance on the consistency and readability of documentation. We treat our
documentation like we treat our code: we aim to improve it as often as possible.
Documentation changes generally come in two forms:
- General improvements: typo corrections, error fixes and better explanations through clearer
writing and more examples.
- New features: documentation of features that have been added to the project since the last
release.
This section explains how writers can craft their documentation changes in the most useful and least
error-prone ways.
How documentation is written
Though SpinKube’s documentation is intended to be read as HTML at https://spinkube.dev/docs, we edit
it as a collection of plain text files written in Markdown
for maximum flexibility.
SpinKube’s documentation uses a documentation system known as docsy, which
in turn is based on the Hugo web framework. The basic idea is that
lightly-formatted plain-text documentation is transformed into HTML through a process known as
Static Site Generation (SSG).
Previewing your changes locally
If you want to run your own local Hugo server to preview your changes as you work:
- Fork the
spinframework/spinkube-docs repository on
GitHub. - Clone your fork to your computer.
- Read the
README.md file for instructions on how to build the site from source. - Continue with the usual development workflow to edit files, commit them, push changes up to your
fork, and create a pull request. If you’re not sure how to do this, see writing code for tips.
Making quick changes
If you’ve just spotted something you’d like to change while using the documentation, the website has
a shortcut for you:
- Click Edit this page in the top right-hand corner of the page.
- If you don’t already have an up-to-date fork of the project repo, you are prompted to get one -
click Fork this repository and propose changes or Update your Fork to get an up-to-date
version of the project to edit.
Filing issues
If you’ve found a problem in the documentation, but you’re not sure how to fix it yourself, please
file an issue in the documentation repository.
You can also file an issue about a specific page by clicking the Create Issue button in the top
right-hand corner of the page.
6.4 - Troubleshooting
Troubleshooting common errors and issues with SpinKube.
The following is a list of common error messages and potential troubleshooting suggestions that
might assist you with your work.
SpinKube Support Policy
SpinKube provides support on a best-effort basis. For users who installed SpinKube manually following the documentation, please report issues in the Spin Operator repository. For installations via the Azure Marketplace, please open an issue in the Azure repository for assistance. If your issue is urgent, feel free to raise it in Slack.
Failure downloading the Helm chart
While the Spin Operator Helm chart is public and can be fetched anonymously, you may run into errors pulling the chart if you’ve previously authenticated with the ghcr.io registry but the authentication token has since expired.
The error would look something like the following:
helm install spin-operator \
--namespace spin-operator --create-namespace --version 0.6.1 --wait oci://ghcr.io/spinframework/charts/spin-operator
Error: INSTALLATION FAILED: failed to download "oci://ghcr.io/spinframework/charts/spin-operator" at version "0.6.1"
To fix, either re-authenticate with the registry with a valid token (e.g. docker login ghcr.io) or log out of the registry and pull the chart anonymously (e.g. docker logout ghcr.io).
No endpoints available for service “spin-operator-webhook-service”
When following the quickstart guide the following error can occur when running the kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
command:
Error from server (InternalError): error when creating "https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml": Internal error occurred: failed calling webhook "mspinappexecutor.kb.io": failed to call webhook: Post "https://spin-operator-webhook-service.spin-operator.svc:443/mutate-core-spinkube-dev-v1alpha1-spinappexecutor?timeout=10s": no endpoints available for service "spin-operator-webhook-service"
To address the error above, first look to see if Spin Operator is running:
get pods -n spin-operator
NAME READY STATUS RESTARTS AGE
spin-operator-controller-manager-5bdcdf577f-htshb 0/2 ContainerCreating 0 26m
If the above result (ready 0/2) is returned, then use the name from the above result to kubectl describe pod of the spin-operator:
kubectl describe pod spin-operator-controller-manager-5bdcdf577f-htshb -n spin-operator
If the above command’s response includes the message SetUp failed for volume "cert" : secret "webhook-server-cert" not found, please check the certificate. The spin operator requires this
certificate to serve webhooks, and the missing certificate could be one reason why the spin operator
is failing to start.
The command to check the certificate and the desired output is as follows:
kubectl get certificate -n spin-operator
NAME READY SECRET AGE
spin-operator-serving-cert True webhook-server-cert 11m
Instead of the desired output shown above you may be getting the No resources found in spin-operator namespace. response from the command. For example:
kubectl get certificate -n spin-operator
No resources found in spin-operator namespace.
To resolve this issue, please try to install the Spin Operator again. Except this time, use the
helm upgrade --install syntax instead of just helm install:
helm upgrade --install spin-operator \
--namespace spin-operator \
--create-namespace \
--version 0.6.1 \
--wait \
oci://ghcr.io/spinframework/charts/spin-operator
Once the Spin Operator is installed you can try and run the kubectl apply -f https://github.com/spinframework/spin-operator/releases/download/v0.6.1/spin-operator.shim-executor.yaml
command again. The issue should be resolved now.
Error Validating Data: Connection Refused
When trying to run the kubectl apply -f <URL> command (for example installing the cert-manager
etc.) you may encounter an error similar to the following:
$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.yaml
error: error validating "https://github.com/cert-manager/cert-manager/releases/download/v1.20.0/cert-manager.yaml": error validating data: failed to download openapi: Get "https://127.0.0.1:6443/openapi/v2?timeout=32s": dial tcp 127.0.0.1:6443: connect: connection refused; if you choose to ignore these errors, turn validation off with --validate=false
This is because no cluster exists. You can create a cluster following the Quickstart guide.
Cluster Already Exists
When trying to create a cluster (e.g. a cluster named wasm-cluster) you may receive an error
message similar to the following:
FATA[0000] Failed to create cluster 'wasm-cluster' because a cluster with that name already exists
With kind installed, you can use the following command to get a cluster list:
$ kind get clusters
wasm-cluster
With `kubectl installed, you can use the following command to dump cluster information (this is much
more verbose):
kubectl cluster-info dump
Cluster Delete
With kind installed, you can delete the cluster by name, as shown in the command below:
kind delete cluster --name wasm-cluster
Too long: must have at most 262144 bytes
When running kubectl apply -f my-file.yaml, the following error can occur if the yaml file is too
large:
Too long: must have at most 262144 bytes
Using the --server-side=true option resolves this issue:
kubectl apply --server-side=true -f my-file.yaml
Redis Operator
Noted an error when installing Redis Operator:
$ helm repo add redis-operator https://spotahome.github.io/redis-operator
"redis-operator" has been added to your repositories
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "redis-operator" chart repository
Update Complete. ⎈Happy Helming!⎈
$ helm install redis-operator redis-operator/redis-operator
Error: INSTALLATION FAILED: failed to install CRD crds/databases.spotahome.com_redisfailovers.yaml: error parsing : error converting YAML to JSON: yaml: line 4: did not find expected node content
Used the following commands to enforce using a different version of Redis Operator (whilst waiting
on this PR fix to be merged).
$ helm install redis-operator redis-operator/redis-operator --version 3.2.9
NAME: redis-operator
LAST DEPLOYED: Mon Jan 22 12:33:54 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
error: requires go version
When building apps like the
cpu-load-gen Spin app, you
may get the following error if your TinyGo is not up to date. The error requires go version 1.18
through 1.20 but this is not necessarily the case. It is recommended that you have the latest
go installed e.g. 1.21 and downgrading is unnecessary. Instead please go ahead and install the
latest version of TinyGo to resolve this error:
user@user:~/spin-operator/apps/cpu-load-gen$ spin build
Building component cpu-load-gen with `tinygo build -target=wasi -gc=leaking -no-debug -o main.wasm main.go`
error: requires go version 1.18 through 1.20, got go1.21
7 - Glossary
Glossary of terms used by the SpinKube project.
The following glossary of terms is in the context of deploying, scaling, automating and managing
Spin applications in containerized environments.
Chart
A Helm chart is a package format used in Kubernetes for deploying applications. It contains all the
necessary files, configurations, and dependencies required to deploy and manage an application on a
Kubernetes cluster. Helm charts provide a convenient way to define, install, and upgrade complex
applications in a consistent and reproducible manner.
Cluster
A Kubernetes cluster is a group of nodes (servers) that work together to run containerized
applications. It consists of a control plane and worker nodes. The control plane manages and
orchestrates the cluster, while the worker nodes host the containers. The control plane includes
components like the API server, scheduler, and controller manager. The worker nodes run the
containers using container runtime engines like Docker. Kubernetes clusters provide scalability,
high availability, and automated management of containerized applications in a distributed
environment.
Container Runtime
A container runtime is a software that manages the execution of containers. It is responsible for
starting, stopping, and managing the lifecycle of containers. Container runtimes interact with the
underlying operating system to provide isolation and resource management for containers. They also
handle networking, storage, and security aspects of containerization. Popular container runtimes
include Docker, containerd, and CRI-O. They enable the deployment and management of containerized
applications, allowing developers to package their applications with all the necessary dependencies
and run them consistently across different environments.
Controller
A Controller is a core component responsible for managing the desired state of a specific resource
or set of resources. It continuously monitors the cluster and takes actions to ensure that the
actual state matches the desired state. Controllers handle tasks such as creating, updating, and
deleting resources, as well as reconciling any discrepancies between the current and desired states.
They provide automation and self-healing capabilities, ensuring that the cluster remains in the
desired state even in the presence of failures or changes. Controllers play a crucial role in
maintaining the stability and reliability of Kubernetes deployments.
Custom Resource (CR)
In the context of Kubernetes, a Custom Resource (CR) is an extension mechanism that allows users to
define and manage their own API resources. It enables the creation of new resource types that are
specific to an application or workload. Custom Resources are defined using Custom Resource
Definitions (CRDs) and can be treated and managed like any other Kubernetes resource. They provide a
way to extend the Kubernetes API and enable the development of custom controllers to handle the
lifecycle and behavior of these resources. Custom Resources allow for greater flexibility and
customization in Kubernetes deployments.
Custom Resource Definition (CRD)
A Custom Resource Definition (CRD) is an extension mechanism that allows users to define their own
custom resources. It enables the creation of new resource types with specific schemas and behaviors.
CRDs define the structure and validation rules for custom resources, allowing users to store and
manage additional information beyond the built-in Kubernetes resources. Once a CRD is created,
instances of the custom resource can be created, updated, and deleted using the Kubernetes API. CRDs
provide a way to extend Kubernetes and tailor it to specific application requirements.
SpinApp CRD
The SpinApp CRD is a Kubernetes resource that extends the functionality of the Kubernetes API to
support Spin applications. It defines a custom resource called “SpinApp” that encapsulates all the
necessary information to deploy and manage a Spin application within a Kubernetes cluster. The
SpinApp CRD consists of several key fields that define the desired state of a Spin application.
Here’s an example of a SpinApp custom resource that uses the SpinApp CRD schema:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: simple-spinapp
spec:
image: "ghcr.io/spinframework/containerd-shim-spin/examples/spin-rust-hello:v0.25.0"
replicas: 1
executor: "containerd-shim-spin"
SpinApp CRDs are kept separate from Helm. If using Helm, CustomResourceDefinition (CRD) resources
must be installed prior to installing the Helm chart.
You can modify the example above to customize the SpinApp via a YAML file. Here’s an updated YAML
file with additional customization options:
apiVersion: core.spinkube.dev/v1alpha1
kind: SpinApp
metadata:
name: simple-spinapp
spec:
image: 'ghcr.io/spinframework/containerd-shim-spin/examples/spin-rust-hello:v0.25.0'
replicas: 3
imagePullSecrets:
- name: spin-image-secret
serviceAnnotations:
key: value
podAnnotations:
key: value
resources:
limits:
cpu: '1'
memory: 512Mi
requests:
cpu: '0.5'
memory: 256Mi
env:
- name: ENV_VAR1
value: value1
- name: ENV_VAR2
value: value2
# Add any other user-defined values here
In this updated example, we have added additional customization options:
imagePullSecrets: An optional field that lets you reference a Kubernetes secret that has
credentials for you to pull in images from a private registry.serviceAnnotations: An optional field that lets you set specific annotations on the underlying
service that is created.podAnnotations: An optional field that lets you set specific annotations on the underlying pods
that are created.resources: You can specify resource limits and requests for CPU and memory. Adjust the values
according to your application’s resource requirements.env: You can define environment variables for your SpinApp. Add as many environment variables as
needed, providing the name and value for each.
To apply the changes, save the YAML file (e.g. updated-spinapp.yaml) and then apply it to your
Kubernetes cluster using the following command:
kubectl apply -f updated-spinapp.yaml
Helm
Helm is a package manager for Kubernetes that simplifies the deployment and management of
applications. It uses charts, which are pre-configured templates, to define the structure and
configuration of an application. Helm allows users to easily install, upgrade, and uninstall
applications on a Kubernetes cluster. It also supports versioning, dependency management, and
customization of deployments. Helm charts can be shared and reused, making it a convenient tool for
managing complex applications in a Kubernetes environment.
Image
In the context of Kubernetes, an image refers to a packaged and executable software artifact that
contains all the necessary dependencies and configurations to run a specific application or service.
It is typically built from a Dockerfile and stored in a container registry. Images are used as the
basis for creating containers, which are lightweight and isolated runtime environments. Kubernetes
pulls the required images from the registry and deploys them onto the cluster’s worker nodes. Images
play a crucial role in ensuring consistent and reproducible deployments of applications in
Kubernetes.
Kubernetes
Kubernetes is an open-source container orchestration platform that automates the deployment,
scaling, and management of containerized applications. It provides a framework for running and
coordinating containers across a cluster of nodes. Kubernetes abstracts the underlying
infrastructure and provides features like load balancing, service discovery, and self-healing
capabilities. It enables organizations to efficiently manage and scale their applications, ensuring
high availability and resilience.
Open Container Initiative (OCI)
The Open Container Initiative (OCI) is an open governance structure and project that aims to create
industry standards for container formats and runtime. It was formed to ensure compatibility and
interoperability between different container technologies. OCI defines specifications for container
images and runtime, which are used by container runtimes like Docker and containerd. These
specifications provide a common framework for packaging and running containers, allowing users to
build and distribute container images that can be executed on any OCI-compliant runtime. OCI plays a
crucial role in promoting portability and standardization in the container ecosystem.
Pod
A Pod is the smallest and most basic unit of deployment. It represents a single instance of a
running process in a cluster. A Pod can contain one or more containers that are tightly coupled and
share the same resources, such as network and storage. Containers within a Pod are scheduled and
deployed together on the same node. Pods are ephemeral and can be created, deleted, or replaced
dynamically. They provide a way to encapsulate and manage the lifecycle of containerized
applications in Kubernetes.
Role Based Access Control (RBAC)
Role-Based Access Control (RBAC) is a security mechanism in Kubernetes that provides fine-grained
control over access to cluster resources. RBAC allows administrators to define roles and permissions
for users or groups, granting or restricting access to specific operations and resources within the
cluster. RBAC ensures that only authorized users can perform certain actions, helping to enforce
security policies and prevent unauthorized access to sensitive resources. It enhances the overall
security and governance of Kubernetes clusters.
Runtime Class
A Runtime Class is a resource that allows users to specify different container runtimes for running
their workloads. It provides a way to define and select the runtime environment in which a Pod
should be executed. By using Runtime Classes, users can choose between different container runtimes,
based on their specific requirements. This flexibility enables the deployment of workloads with
different runtime characteristics, allowing for better resource utilization and performance
optimization in Kubernetes clusters.
Scheduler
A scheduler is a component responsible for assigning Pods to nodes in the cluster. It takes into
account factors like resource availability, node capacity, and any defined scheduling constraints or
policies. The scheduler ensures that Pods are placed on suitable nodes to optimize resource
utilization and maintain high availability. It considers factors such as affinity, anti-affinity,
and resource requirements when making scheduling decisions. The scheduler continuously monitors the
cluster and makes adjustments as needed to maintain the desired state of the workload distribution.
Service
In Kubernetes, a Service is an abstraction that defines a logical set of Pods that enables clients
to interact with a consistent set of Pods, regardless of whether the code is designed for a
cloud-native environment or a containerized legacy application.
Spin
Spin is a framework designed for building and running event-driven microservice applications using
WebAssembly (Wasm) components.
SpinApp Manifest
The goal of the SpinApp manifest is twofold:
- to represent the possible options for configuring a Wasm workload running in Kubernetes
- to simplify and abstract the internals of how that Wasm workload is executed, while allowing the
user to configure it to their needs
As a result, the simplest SpinApp manifest only requires the registry reference to create a
deployment, pod, and service with the right Wasm executor.
However, the SpinApp manifest currently supports configuring options such as:
- image pull secrets to fetch applications from private registries
- liveness and readiness probes
- resource limits (and requests*)
- Spin variables
- volume mounts
- autoscaling
Spin App Executor (CRD)
The SpinAppExecutor CRD is a Custom Resource Definition
utilized by Spin Operator to determine which executor type should be used in running a SpinApp.
Spin Operator
Spin Operator is a Kubernetes operator in charge of handling the lifecycle of Spin applications
based on their SpinApp resources.